我的一个github开源项目star数过百了,非常开心,感谢大家。
前言¶
前面只顾着讲算法,讲损失,讲训练参数设置和细节,缺忽视了一个重要的东西,那就是目标检测的评价标准是什么?这一节,我们就来搞懂这个问题。
评价指标¶
1.准确率(Accuracy)¶
检测时分对的样本数除以所有的样本数。准确率一般被用来评估检测模型的全局准确程度,包含的信息有限,不能完全评价一个模型性能。
2.混淆矩阵(Confusion Matrix)¶
混淆矩阵是以模型预测的类别数量统计信息为横轴,真实标签的数量统计信息为纵轴画出的矩阵。对角线代表了模型预测和数据标签一致的数目,所以准确率也可以用混淆矩阵对角线之和除以测试集图片数量来计算。对角线上的数字越大越好,在混淆矩阵可视化结果中颜色越深,代表模型在该类的预测结果更好。其他地方自然是预测错误的地方,自然值越小,颜色越浅说明模型预测的更好。
3.精确率(Precision)和召回率(Recall)和PR曲线¶
一个经典例子是存在一个测试集合,测试集合只有大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。然后就可以定义:
- True positives: 简称为TP,即正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
- True negatives: 简称为TN,即负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
- False Positives: 简称为FP,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
- False negatives: 简称为FN,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
精确率就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例,公式如下: Precision=\frac{TP}{TP+FP}=\frac{TP}{N},其中N代表测试集样本数。
召回率是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值,公式如下: Recall=\frac{TP}{TP+FN}
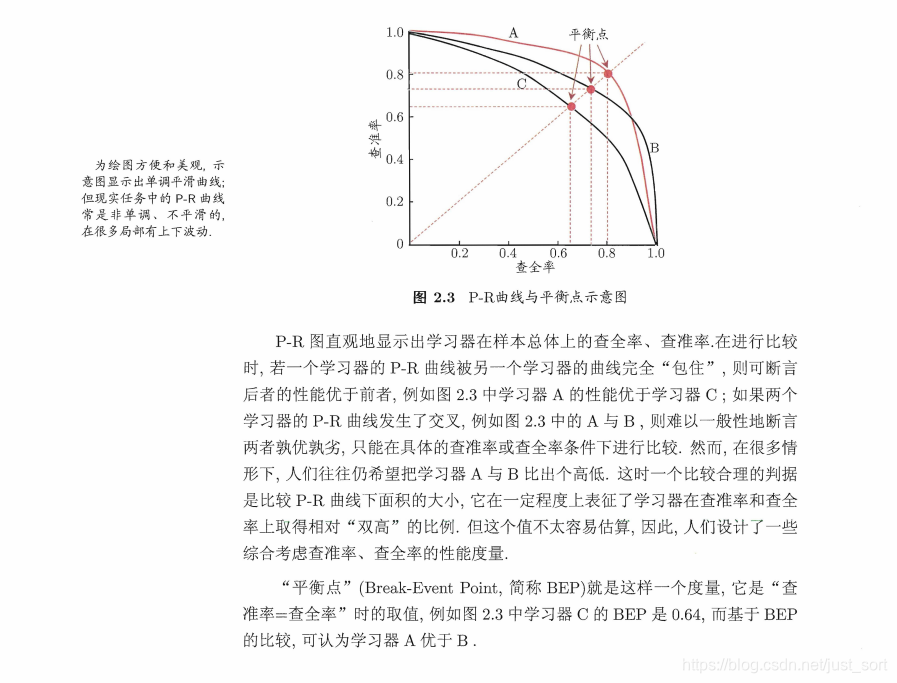
所谓PR曲线就是改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。曲线图大概如下,这里有3条PR曲线,周志华机器学习的解释如下:
4.平均精度(Average-Precision,AP)和mAP¶
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。 mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
5.ROC曲线¶
如下图所示:
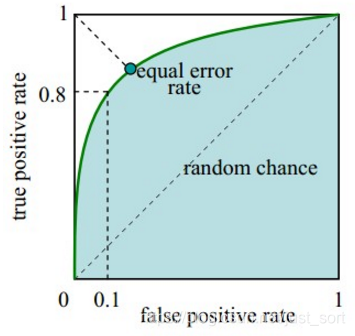
ROC的横轴是假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率。 ROC的纵轴是真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。 ROC曲线的对角线坐标对应于随即猜测,而坐标点(0,1)也即是左上角坐标对应理想模型。曲线越接近左上角代表检测模型的效果越好。
那么ROC曲线是怎么绘制的呢?有如下几个步骤: - 根据每个测试样本属于正样本的概率值从大到小排序。 - 从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。 - 每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。 当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
6.AUC(Area Uner Curve)¶
即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。AUC的计算公式如下:
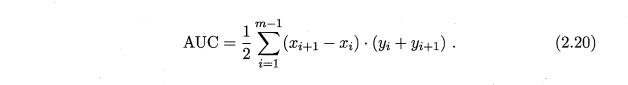
PR曲线和ROC曲线选用时机¶
目标检测中用的最多的是MAP值,但我们最好再了解一下PR曲线和ROC曲线的应用场景,在不同的数据集中选择合适的评价标准更好的判断我们的模型是否训好了。
PR曲线¶
从PR的计算公式可以看出,PR曲线聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
ROC曲线¶
当测试集中的正负样本的分布发生变化时,ROC曲线可以保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。但是在关心正例的预测准确性的场景,ROC曲线就不能更好的反应模型的性能了,因为ROC曲线的横轴采用FPR,根据FPR公式 ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。
因此,PR曲线和ROC曲线的选用时机可以总结如下:

从目标检测任务来讲,一般关心MAP值即可。
数据集介绍¶
刚才介绍了目标检测算法的常见评价标准,这里再介绍一下目标检测常用的数据集。以下介绍来自于github工程整理:DeepLearning-500-questions
PASCAL VOC数据集¶
VOC数据集是目标检测经常用的一个数据集,自2005年起每年举办一次比赛,最开始只有4类,到2007年扩充为20个类,共有两个常用的版本:2007和2012。学术界常用5k的train/val 2007和16k的train/val 2012作为训练集,test 2007作为测试集,用10k的train/val 2007+test 2007和16k的train/val 2012作为训练集,test2012作为测试集,分别汇报结果。
MSCOCO数据集¶
COCO数据集是微软团队发布的一个可以用来图像recognition+segmentation+captioning的数据集,该数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展。依托这一数据集,每年举办一次比赛,现已涵盖检测、分割、关键点识别、注释等机器视觉的中心任务,是继ImageNet Chanllenge以来最有影响力的学术竞赛之一。
相比ImageNet,COCO更加偏好目标与其场景共同出现的图片,即non-iconic images。这样的图片能够反映视觉上的语义,更符合图像理解的任务要求。而相对的iconic images则更适合浅语义的图像分类等任务。 COCO的检测任务共含有80个类,在2014年发布的数据规模分train/val/test分别为80k/40k/40k,学术界较为通用的划分是使用train和35k的val子集作为训练集(trainval35k),使用剩余的val作为测试集(minival),同时向官方的evaluation server提交结果(test-dev)。除此之外,COCO官方也保留一部分test数据作为比赛的评测集。
Google Open Image数据集¶
pen Image是谷歌团队发布的数据集。最新发布的Open Images V4包含190万图像、600个种类,1540万个bounding-box标注,是当前最大的带物体位置标注信息的数据集。这些边界框大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。另外,这些图像是非常多样化的,并且通常包含有多个对象的复杂场景(平均每个图像 8 个)。
ImageNet数据集¶
ImageNet是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。ImageNet是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
DOTA数据集¶
DOTA是遥感航空图像检测的常用数据集,包含2806张航空图像,尺寸大约为4kx4k,包含15个类别共计188282个实例,其中14个主类,small vehicle 和 large vehicle都是vehicle的子类。其标注方式为四点确定的任意形状和方向的四边形。航空图像区别于传统数据集,有其自己的特点,如:尺度变化性更大;密集的小物体检测;检测目标的不确定性。数据划分为⅙验证集,⅓测试集,½训练集。目前发布了训练集和验证集,图像尺寸从800x800到4000x4000不等。
后记¶
本文介绍了目标检测算法中的常见标准和常见的目标检测评测数据集,算是对各种论文解读文章细节的一个补充,希望能够熟记最主要的评测指标和常用的几个数据集,一般来讲顶会论文的实验部分都会以介绍的这几个数据集为基准测评表现。
参考¶
https://www.cnblogs.com/eilearn/p/9071440.html
https://github.com/scutan90/DeepLearning-500-questions
《周志华:机器学习》
欢迎关注我的微信公众号GiantPadaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次