新进展!Larimar-让大型语言模型像人一样记忆与遗忘¶
1. 论文摘要¶
更新大型语言模型(LLM)中的知识是当前研究的一个重要挑战。本文介绍了Larimar——一种受大脑启发的新架构,它通过分布式情节记忆来增强LLM。Larimar的记忆系统能够在不需要重新训练或微调的情况下,动态地进行一次性知识更新。在多个事实编辑基准测试中,Larimar展示了与最有竞争力的基线相当的精度,即使在连续编辑的挑战性环境中也是如此。它在速度上也超过了基线,根据不同的LLM,可以实现4到10倍的加速。此外,由于其架构的简单性、LLM不可知论和通用性,Larimar也展示出了灵活性。我们还提供了基于Larimar的一次性记忆更新机制,包括选择性事实遗忘和输入上下文长度的泛化机制,并证明了它们的有效性。
论文标题:Larimar: Large Language Models with Episodic Memory Control
论文链接:https://arxiv.org/abs/2403.11901
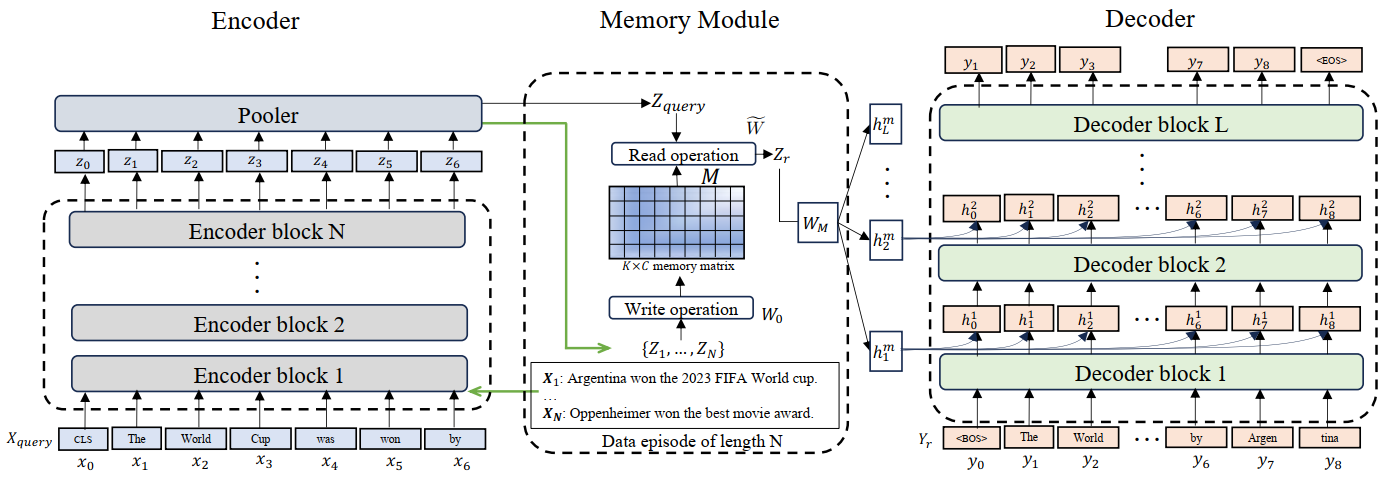
图1: Larimar模型架构概览
2. 背景介绍¶
预训练的大型语言模型(LLM)在多种自然语言处理(NLP)任务中表现出色,并常被视为知识存储库。为了维护这些模型在部署后的事实准确性、安全性和道德性,不断更新LLM中的知识变得至关重要。因此,开发能够快速更新LLM的有效机制显得尤为关键,以确保模型能够保护隐私、消除偏见和跟进新事实的发展。模型编辑应当能够移除LLM“记忆”中不再需要的、错误的或过时的信息,并可选择性地替换为新的事实。同样,快速更新LLM的能力对于解决输入上下文长度泛化的挑战也非常有帮助,特别是在长上下文实例稀缺的数据集中学习时。一个直接的解决方案是在修正后的或新的数据集上对模型进行微调,但这种方法可能导致过度拟合和灾难性遗忘,因为知识是分布式地编码在LLM参数中的。已有研究提出了有效且精确的LLM编辑方法,包括训练辅助外部记忆模型或超网络模型与冻结的LLM并行工作,或者在LLM特征中定位原始事实,然后对相应的权重参数进行局部更新。这两种方法都存在可扩展性问题,因为它们需要重新训练或定位新状态,从而减慢了编辑速度。高内存需求用于存储多个编辑,进一步限制了在连续和批量编辑设置中扩大LLM更新规模的能力。这些挑战限制了在实际工业环境中更新大型语言模型的应用。此外,在处理事实编辑和选择性事实遗忘方面,即使是最先进的编辑方法也面临挑战,而在大脑中,新信息的学习和旧信息的遗忘是相互关联的。
相比之下,人类能够迅速更新知识并泛化,这与第一次接触相关实例后的快速学习相似。在大脑中,这种快速学习能力依赖于海马体及其情节记忆功能。补充学习系统(CLS)理论解释了大脑中快速(海马体)和慢速(新皮层)学习系统的耦合,前者从单个实例中学习,而后者对输入分布进行建模。此外,海马体到新皮层的记忆巩固是通过与海马体中编码的体验多次精确或虚假重放的同步激活来促进的,这表明海马体呈现出生成联想网络的形式。
受到这些见解的启发,我们提出了Larimar——一种通过外部情节记忆控制器增强的LLM。我们遵循CLS的观点:一个海马快速学习系统将样本记录为情节记忆,而一个新皮层慢速学习系统(LLM)学习输入分布的总结统计作为语义记忆。我们的目标是将情节记忆模块作为当前一组事实更新或编辑的全局存储,并将此记忆强制应用于LLM解码器。重要的是要学会高效、准确地更新这种记忆,而无需经过任何训练,因为新的编辑会不断到来。

表1: 各种编辑方法的需求与能力对比分析
3. 方案提出¶
为了解决上述问题,我们寻求利用一种分层记忆,其灵感类似于Kanerva机器,其中记忆的写入和读取被解释为生成模型中的推理。具体而言,我们考虑了将记忆视为确定性的记忆模型,从而允许将Kanerva机器中提出的记忆和地址的贝叶斯更新重新形式化为寻找线性系统的最小二乘解。一旦更新,这种快速学习的记忆就会被用来对缓慢的LLM解码器施加条件。
与一组样本相关联的全局记忆,以及快速写入内存的能力,使得这种分层记忆框架对于LLM有效更新新知识非常有吸引力。在实现方面,记忆通过对通用数据进行端到端梯度下降与LLM耦合,并且不需要访问编辑。在推理期间,新数据以一次性方式写入内存,更新后的记忆然后对LLM解码进行条件化,以强制执行编辑输出。我们进一步在Larimar的一次性记忆更新机制的基础上形式化了无需训练的选择性事实遗忘和防止信息泄露的操作方式。
据我们所知,这是第一项提出并展示在线分布式写入分层条件记忆模型作为LLM测试时间适应新知识解决方案的工作。我们在现有基准上针对单一和连续事实编辑任务展示了Larimar,并与基线方法进行了比较。Larimar在这些设置中提供了准确和精确的编辑,同时速度比竞争性的模型编辑基线快10倍。我们进一步展示了Larimar在选择性事实遗忘和防止信息泄漏任务中的有效性。最后,我们提供了一种简单的基于递归搜索的解决方案,使Larimar的记忆能够推广到较长的输入上下文。
4. 模型架构¶
符号: 我们将输入和输出空间定义为X和Y,分别。该模型包括一个编码器e:X\rightarrow R^C和一个解码器d:R^C\rightarrow Y,通过一个自适应记忆相连。编码器在C维潜在空间中输出。记忆使用K行来存储长度为N的编码事件,初始状态为M_0\in R^{K\times C},并通过读取和写入权重W,W_0\in R^{N\times K}进行更新,从而产生更新后的记忆M。
4.1. 训练¶
给定记忆M,Kanerva机器的目标是最大化条件对数似然\ln p(X|M),其中X是一个可交换(顺序不变)的事件:X=\{x_1,...,x_N\},是输入数据的一个子集,包含N个样本。这个条件似然函数的变分下界正在被优化,这一过程与变分自动编码器中的操作类似。因此,该模型学会将X压缩到记忆M中,M随后成为一个分布式关联式记忆。实际上,M是在Z+ξ的噪声版本上学习的,其中Z=e(X)表示一个事件。在本研究的其余部分,我们使用M表示依赖于一个事件X的后验记忆,而M_0表示先验记忆。读取权重矩阵W被视为一个随机变量,以强制模型的生成能力,对此我们使用标准高斯先验p(W)\sim N(0,I_{N\times K})和后验q(W)\sim N(\overline{W},\sigma ^2_W\cdot I_{N\times K}),其中均值\overline{W}是从每个事件估计的,而\sigma_W是可学习参数。记忆读出结果被获得为Z_{readout}=WM。整个增强记忆的架构如图1所示。
在训练期间,编码器(e)、关联记忆(M)和解码器(d)三个模块都是根据一个事件X联合训练和优化的,使用以下损失函数:
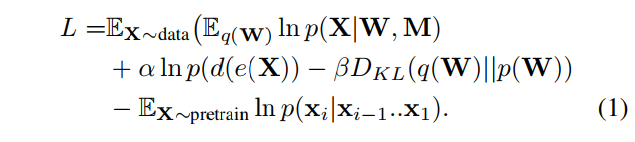
第一项是具有记忆和W(一个N×K矩阵)的负重构损失。第二项是自动编码器在没有记忆的情况下的负重构损失。第三项是先验p(W)和后验q(W)之间的KL散度。为了在训练期间维持解码器的性能,添加了一个来自预训练数据的正则化项。
4.2. 记忆推理¶
一旦M_0通过反向传播进行了训练,则后验记忆M就通过求解一个最小化问题,我们使用\min_M||Z_\zeta-W_0M||^2_F来进行一次性更新。这个最小化问题对应于求解一个线性方程组,可以通过计算矩阵伪逆有效地解决。
实现: 我们采用了一个BERT large编码器,结合了一个GPT2-large或GPTJ-6B解码器和一个记忆矩阵(512x768),用于我们的训练实验,将生成的模型命名为Larimar-1.3B和Larimar-6B, 分别。我们的训练数据包含760万个示例,由将WikiText文本分割成小块(64个标记)构建而成。在测试中,Larimar-1.3B模型在1000个随机WikiText样本上达到了14.6的困惑度,而Larimar-6B模型达到了15.9,表明添加记忆几乎不会影响性能。我们使用Adam优化器、学习率5e-6和批量大小32,训练Larimar-6B模型10个周期。对于Larimar-6B的训练,我们使用了一个设置,包括单节点上的8个NVIDIA A100-80GB GPU,利用bfloat16精度和PyTorch Lightning,结合DeepSpeed ZeRO Stage 2进行高效的分布式训练。
5. 记忆操作¶
写入、读取和生成操作 作用于Z编码的三个基本记忆操作“写入、读取和生成”被转化为(Pham et al., 2021)中所述。
连续写入和遗忘 给定一组初始编码Z_0和写入权重W_0,我们初始化记忆矩阵和键协方差矩阵:
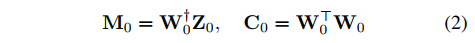
为了连续更新记忆M_{i-1},要么添加一组新的编码Z_i,要么遗忘之前写入的一组编码Z_i,我们联合更新记忆矩阵和键协方差矩阵,对于i=1,2,...:

当写入新编码到记忆时,我们使用\alpha_i=1。当遗忘之前用\alpha_{i_{write}}=1写入记忆的任何i_{write}<i的编码时,我们使用\alpha_i=-1。等式(4)以这样一种方式连续更新记忆,即它保持对于不断增长的序列数据的最小二乘解。假设M_{i-1}是对于编码Z_{0:i-1}的最小二乘解,即

那么等式(4)中的\alpha_i=1确保M_i同样是对于Z_{0:i}的最小二乘解。在情况\alpha_i=-1和Z_i=Z_{i_{forget}}对于某个i_{forget}<i时,等式(4)确保M_i是在从数据中移除Z_{i_{forget}}后的最小二乘解,即

权重可以根据当前记忆计算,W_i=Z_iM_{i-1}^{\dagger},或根据固定的参考记忆计算,W_i=Z_i(M^{(ref)})^{\dagger}。M^{(ref)}在所有连续更新过程中保持不变(即与i无关),仅在推理期间使用,并且可以(可选)使用推理期间遇到的数据构建。如果我们希望从记忆中删除一个之前写入的特定编码,则M^{(ref)}的固定性质允许在之后的序列i_{forget}>i_{write}的某一点重新计算原始写入键W_{i_{write}},以便定位记忆中的信息并将其删除。
6. 范围检测器¶
我们进一步引入了一个可选的范围检测机制,用于判断传入的查询是否与记忆中记录的事实相近似,这一机制在理念上与SERAC相似。如果查询落在预定范围内,相应的记忆内容会被读取并传递给解码器,以便进行基于记忆的条件性解码;如果不在范围内,则进行常规的无条件解码。我们考虑了以下两种情况:
基于外部编码的范围检测器(ESD):利用在11亿个句子对上训练得到的外部句子编码器(MiniLM)来估计样本嵌入,其输出空间的维度为384。ESD将编码后的事实以向量形式存储在其范围存储中。在测试阶段,对于给定的编码输入句子,通过计算与1-最近邻余弦相似度来得出检测分数。对于包含多个句子的输入,系统会先将其拆分为单独的句子,分别处理每个句子,并采用最高的相似度分数。在EasyEdit数据集的3800个正负样本上的测试中,ESD模型实现了2.9%的等错误率和0.974的F1分数。
基于内部编码的范围检测器(ISD):使用Larimar编码器e来嵌入CounterFact样本。随后,利用这些编码来训练一个二元范围分类器,正样本源自对原始事实的重新表述,而负样本则对应于接近的事实。
7. 结果展示¶

表2: 在CounterFact数据集上,Larimar与其他基线方法在单一事实编辑任务的性能比较
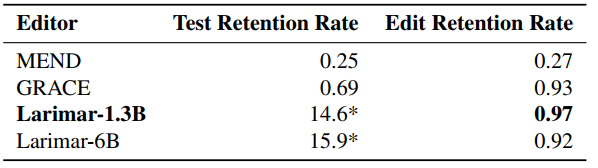
表3: 在ZsRE数据集上进行连续事实编辑时,Larimar保持对旧编辑记忆的能力

图2: 在CounterFact数据集上进行批量事实编辑的准确度分析

图3: 在ZsRE数据集上完成3000次编辑后,Larimar在处理未见过的重述样本时的平均F1分数,证明其在两个数据集上(分别含有1000个和511个独立事实,每个事实有10个或约20个重述版本)的优越泛化性能

表4: 在CounterFact和ZsRE数据集上,经过N次事实写入后移除特定事实,Larimar准确召回事实的能力

表5: 在CounterFact样本上,针对输入重述的攻击成功率分析(预算限制为20)
8. 总结¶
在本项研究中,我们探索了结合大型语言模型(LLM)与动态可更新的分布式情节记忆,作为在线知识更新的新途径。我们的框架采用一次性记忆更新机制和基于记忆的解码条件,展现出在编辑性能上超越传统方法的准确性、精确性和稳定性,速度也显著更高,这些优势不仅体现在单个事实的编辑上,也同样适用于连续序列编辑的复杂场景。此外,我们的记忆更新机制还能够实现快速且选择性的事实遗忘和高效的信息删除。我们还提出了一种简便的处理长输入上下文的方法,通过在Larimar的记忆空间中进行递归读取,证明了其在回忆长输入上下文中的事实方面,相较于在更大训练上下文窗口中训练的最新LLM,有着更好的表现。
本文总阅读量次