OpenAI Superalignment的一种途径——Weak-to-Strong Generalization
OpenAI:Superalignment的一种途径——Weak-to-Strong Generalization¶
IIya在OpenAI出大新闻之前在好多场合讲了要推进“Superalignment”,而且OpenAI提出要投入1000万美元来资助superhuman AI alignment。虽然不知道动荡以后OpenAI还会不会在这个方面投入,但是大佬既然都这么看好这个方向,那么我这种灌水小将怎么能放弃这个蹭热点的机会呢?跟着读一读找一找机会应该还是可以的吧?看简中互联网上讨论这个topic的内容比较少,来简单解读下OpenAI去年12月在相关领域发表的第一篇论文——Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision ,然后分享下个人关于还可以怎么做的拙见。
用weak supervision训练的strong models性能超过了supervisor
本文大概分为四个部分,第一部分介绍下OpenAI提出来的Superalignment的概念,第二部分介绍论文提出的Weak-to-Strong Generalization的框架和实验结果,第三部分介绍可能和本文相关的一些工作,第四部分介绍笔者关于未来可以怎么follow up的一些拙见。
主要参考OpenAI的论文和文档:
Weak-to-Strong Generalization Research directions Weak-to-Strong Generalization Blog Weak-to-Strong Generalization Paper Weak-to-Strong Generalization Code
1. 什么是Superalignment?¶
人工智能的三个阶段Superalignment
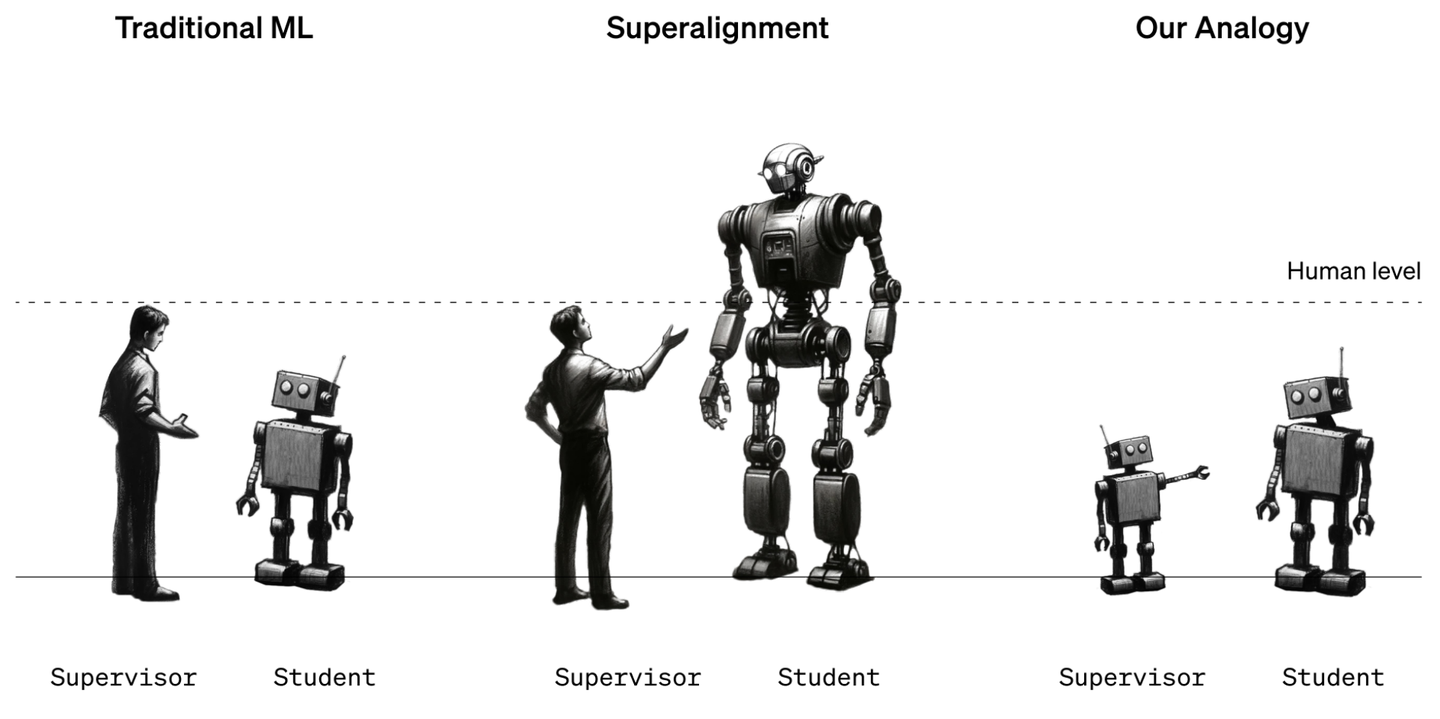
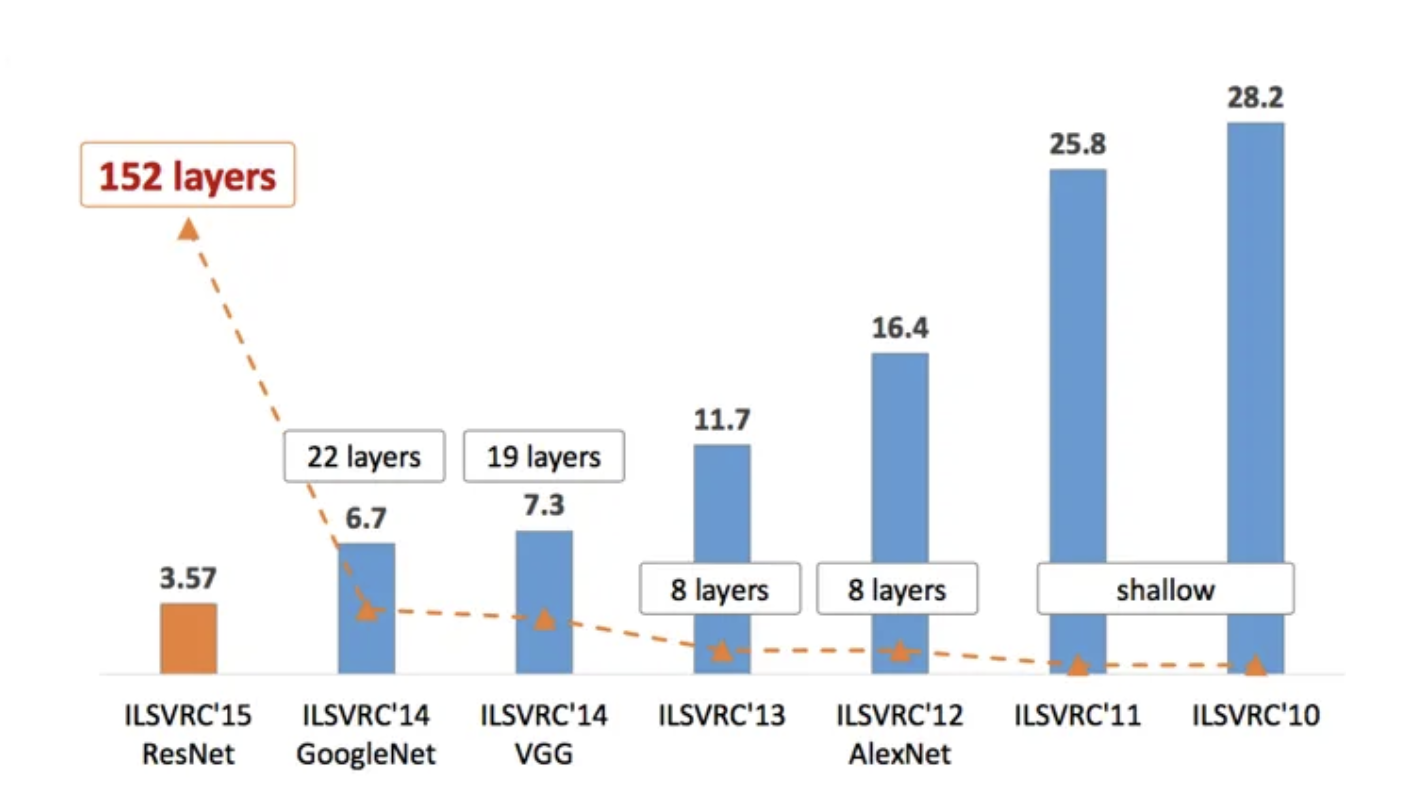
第一阶段就是传统的ML设定,就是靠人来标注数据集,然后利用全监督的数据集完成训练,使得机器能接近人的表现。虽然这个过程现在听起来很简单,然而这一过程也走的相当不易,比如在图像识别这一领域,笔者个人心中深度学习爆发的起点——AlexNet,大家才通过利用Neural Networks(NN)在ImageNet的图像分类比赛中,才逐渐接近人类标分类的正确度,然后到了2015年的ResNet,NN才第一次击败人类标注者。
早期传统ML深度学习网络的演化过程和性能
但是距离AlexNet和ResNet的诞生已经过去了十年,但也仅仅过去了十年,我们几乎可以说深度学习已经走到了第二个阶段——用来自人类supervisor的监督信号来训练出超人类的模型。GPT-3的成功说明了,基于大规模的预训练可以让模型具有很强的reasoning和in-context learning的能力,这似乎是一条切实可行得完成super-human model的路径。而得益于整个community的共同努力,当然努力不仅仅限于算法层面,包括算力、框架、数据收集和清洗等等方面,AI的能力也和英伟达的股价一起起飞了。现如今,无论是GPT-4表现出的强大的reasoning和in-context learning的能力,或是Midjourney基于文字生成的很惊艳的图片,还是前段时间刷屏的Sora视频,在直觉上都让我们有理由相信,利用现有的数据,在很多领域,人类已经可以获得超出人类能力的模型了。

GPT-4理解梗图

Midjourney生成的图像
那么下一步呢?记得之前看过一个几位巨佬的Panel Discussion ,ta们讨论过一个话题:人类如果穷尽了所有的文本用于预训练,那么下一步,model该怎么改进呢(具体巨佬们怎么说可以参考视频)?OpenAI的这个team给出了自己提出的一种可能——WEAK-TO-STRONG GENERALIZATION.
什么叫WEAK-TO-STRONG GENERALIZATION?简单来说,就是在很多特别特别复杂的问题上,人类相较于现有的一些foundation model也有些相形见绌了,即使是最资深的Software Develop Engineer,我觉得似乎也不敢保证自己在一大串代码中找bug的速度要超过GPT-4。那么很自然而然得,他们自然就提出了:
Can we use weak models to supervise strong models?
能否利用性能比较弱的模型来给更强的模型提供监督信号呢?
这篇论文讨论了一个面对的挑战:如何在情况下,当我们(作为人类)不如我们想要监督的模型聪明时,还能有效地监督它们。这个问题被称为从弱到强的学习问题,意味着如何使一个能力较弱的监督者能够有效指导一个比它更强大的学习模型。
为什么这个问题重要呢?OpenAI的报告里提出了以下几个问题:
Strong pretrained models should have excellent latent capabilities—but can we elicit these latent capabilities with only weak supervision? Can the strong model generalize to correctly solve even difficult problems where the weak supervisor can provide only incomplete or flawed training labels? Deep learning has been remarkably successful in his representation learning and generalization properties—can we nudge them to work in our favor, finding methods to improve generalization?
强大的预训练模型应该具有出色的潜在能力,但是我们可以仅通过weak supervision来激发这些潜在能力吗?基于不完整或有缺陷的weak labels,strong model能否泛化来正确解决这些问题? 深度学习在representation learning和generalization properties方面取得了巨大成功——我们能否基于此找到提高generalization能力的方法?
2. Weak-to-Strong Generalization¶
为了解决这个问题,作者提出了一个方法,其核心思想是使用一个较弱的模型来充当supervisor。具体做法分为三个步骤:
- Create the weak supervisor:通过在已知正确答案的数据上训练一个小型的模型来实现。这个模型虽然不是非常强大,但它能对一些数据做出预测,这些预测结果被称为weak labels。
- Train a strong student model with weak supervision:接着,使用这些弱标签来训练一个更强大的模型。这一步的目的是看看这个强模型能从弱监督者那里学到多少,即它的性能能提高到什么程度。
- Train a strong model with ground truth labels as a ceiling:最后,为了评估这种方法的效果,研究者们还会直接用正确的答案(ground truth)来训练一个强模型,以此作为性能的上限对比。
简而言之,这项研究通过一个创新的方法来探索如何让不那么聪明的监督者(在这里是一个小型模型)能够有效地指导更强大的模型学习,同时通过比较实验来衡量这种方法的有效性。
那怎么基于此来评估weak-to-strong learning的效果呢?作者提出了一个很简单直接的指标PGR(Performance Gap Recovered),用来评估在弱监督下训练出来的模型(strong student)与强监督下训练出来的模型(strong ceiling)之间的性能差距中能够恢复多少部分。
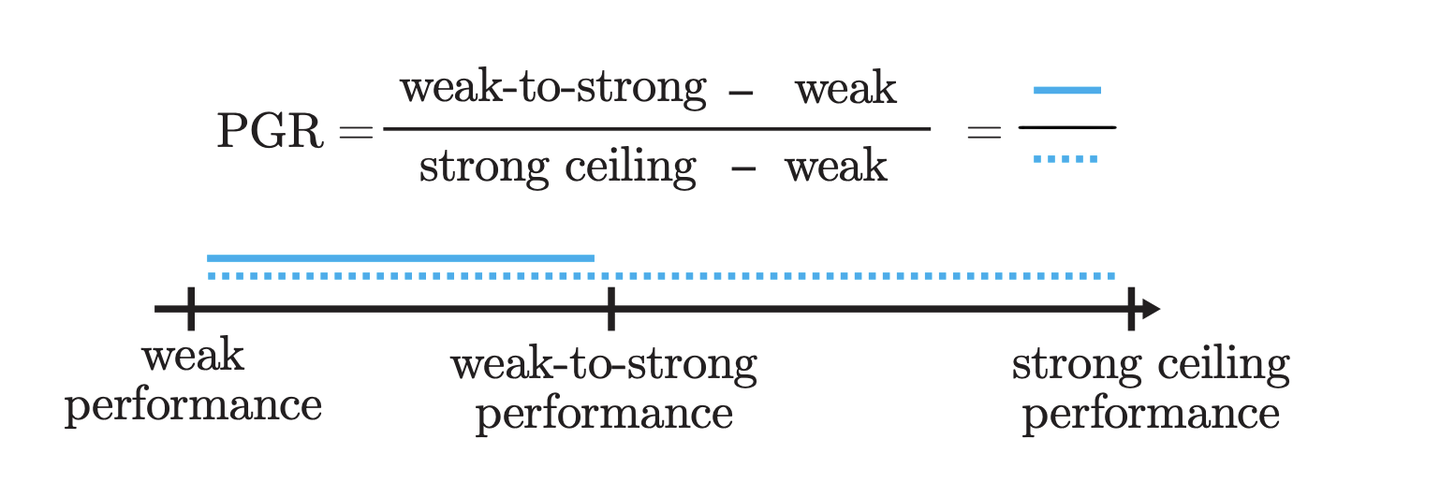
PGR的定义
PGR就是一个衡量标准,用来看我们用不太准确的信息(弱标签)训练出来的模型表现得如何,和用准确信息(真实标签)训练出来的模型比起来。如果PGR数值很高,意味着我们即便没有用最好的信息,模型还是表现得不错;如果PGR很低,那就表示模型没能好好地从不太准确的信息中学习。
那这个metric有什么优缺点呢?PGR的方法有其明显的优点。首先,这种方法的灵活性极高,因为它可以使用任何一对weak-strong模型进行研究,所以不必非要每组实验都上GPT-4。而且由于不需要与人类进行evaluation,我们可以快速地得到实验反馈。然后这种方法适用于各种任务。最后,这种方法在开发出super-human模型之前就已经非常有用了;比如,如果我们能找到方法仅使用GPT-3级别的监督来GPT-4的alignment,这将极大地便利当前的模型对齐工作。实践中来讲,很多模型采用RLHF的模型来进行alignment的时候,reward model的参数量都是显著小于action model的 ,既然这在RLHF中是make sense的,那么相较于reward这种监督信号更加直接的weak labels,也是很有可能可以完成相应的alignment的。
但作者也提出了这个指标的一些局限性。例如,Imitation saliency:未来的super-human模型很可能会对人类行为有非常显著的表征,但我们现有的强模型可能还没有学到足够的特征来模仿弱模型的预测,这意味着在当前的setting,简单地模仿弱监督者可能是一个更容易避免的错误。而且当前弱模型所犯的错误类型可能与未来人类在监督超人类模型时所犯的错误类型不同。Pretraining leakage:我们的预训练数据隐含了人类的监督信息,这可能让我们过于容易地调用强模型的能力,因为这些模型是直接被训练来观察到强(人类水平)的表现的。与此相对,超人类水平的性能可能没有以同样的方式直接被观察到,因为它可能是从自监督学习中获得的,所以未来要从超人类模型中引出这些能力可能会更加困难。
那有没有更好的metric来避免这个问题呢?那答案当然是——俺也不知道。
任务设定¶
- Popular natural language processing benchmarks: 这些是评估NLP模型在诸如道德、常识推理、自然语言推理、情感分析等领域的22个流行的文本分类数据集,所有数据集都被转换为二分类任务,并尽量平衡类别,弱模型用来产生软标签。
- Chess puzzles: 使用lichess.org网站上的棋谱数据集,每个谜题包含一个棋盘位置和解决谜题的最优移动序列,评估任务是预测在给定棋局中的最佳首次移动,这是一个生成任务而不是二分类任务。
- ChatGPT reward modeling: 现今模型对齐的标准方法是基于人类反馈的强化学习(RLHF),其中一个关键步骤是训练一个奖励模型(RM)来预测人类对模型回应的preference,最后使用强化学习优化assistant模型,本工作假设目标是最大化RM的准确性,而不是研究RL步骤。(虽然由于reward hacking的存在,只进行到RM阶段而不完成RLHF有点不一定靠谱,但是完成RLHF这一步的确工作量有点太大了,训过LLM的PPO的朋友应该都能理解......)
实验表现¶
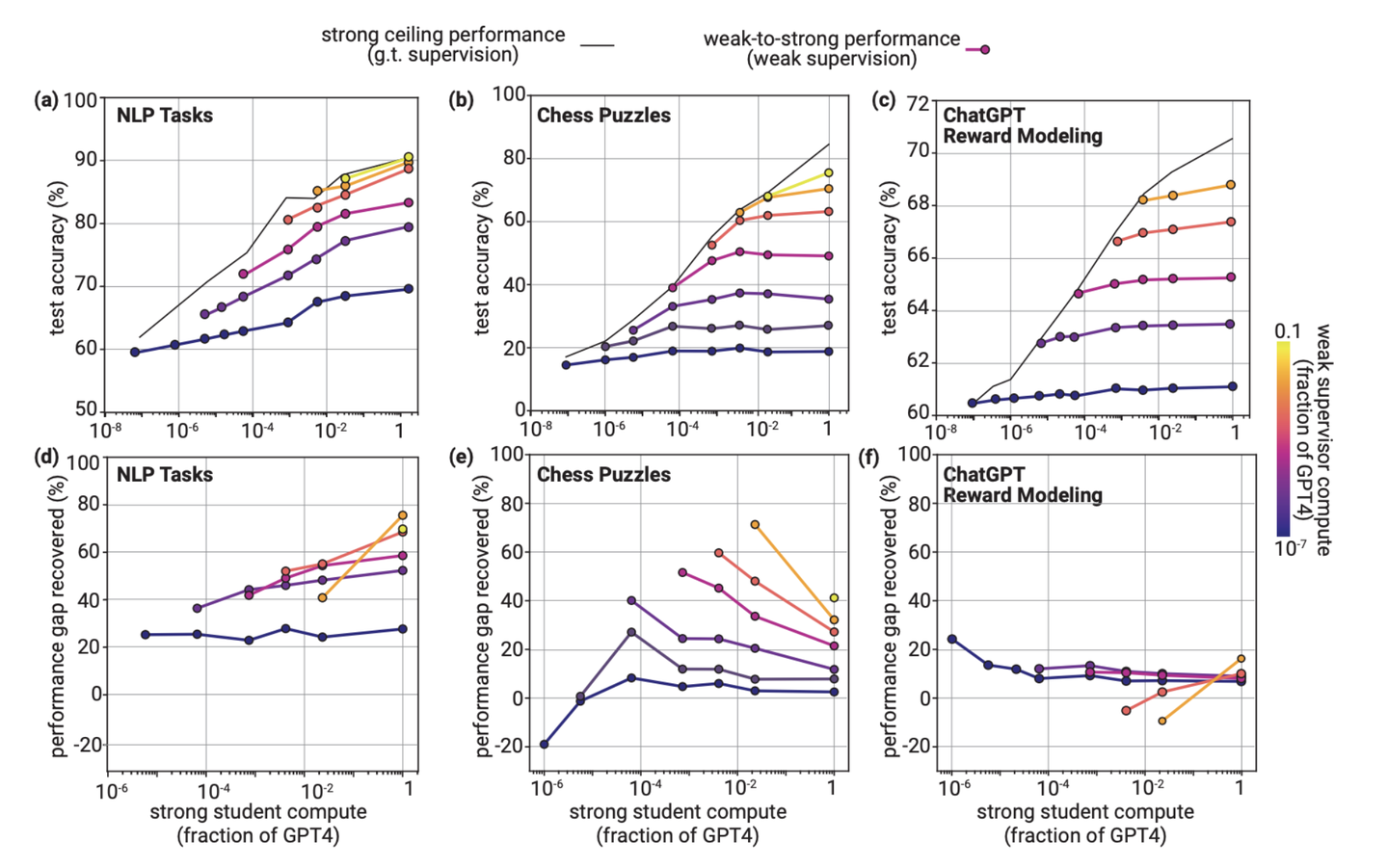
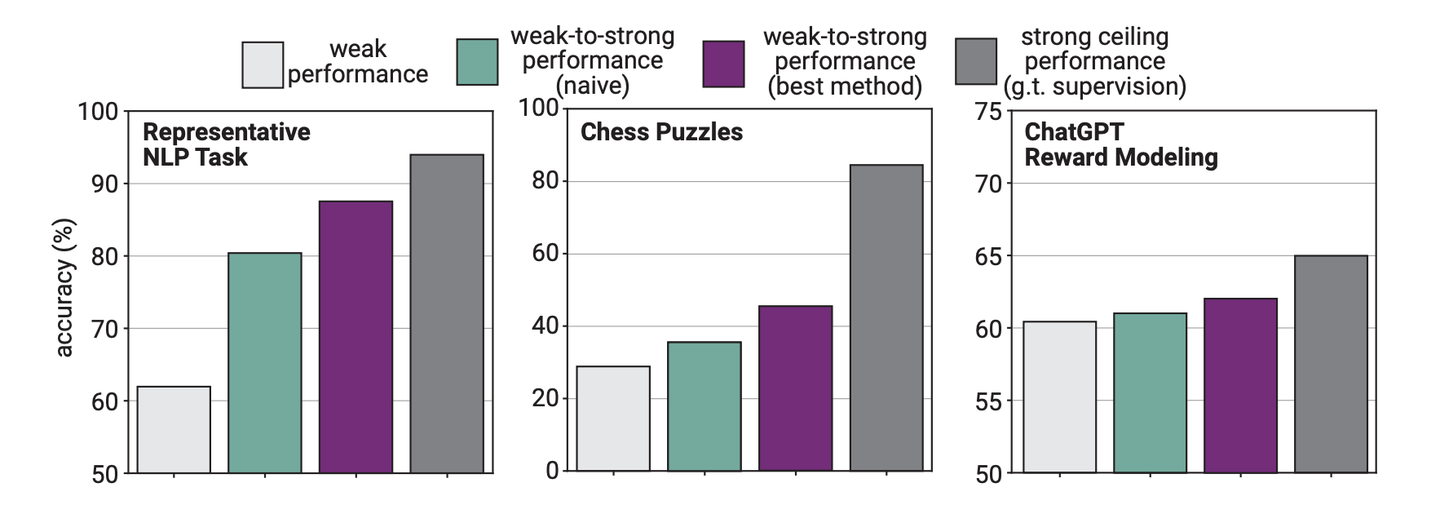
naively finetuning实验结果:traditional NLP和chess puzzles表现较好,但 reward modeling 不好
首先来看最基础的naively finetuning的实验结果。上图的实验结果展示了在traditional NLP和chess puzzles上,通过简单fine-tune就可以实现从Weak-to-Strong Generalization,但是在ChatGPT reward modeling任务上,Generalization表现较差。具体来说:
- traditional NLP和chess puzzles:这些领域的实验结果表明,即使是使用较弱的监督,强student模型也能通过简单微调达到令人满意的泛化水平。对于自然语言处理任务,实验甚至观察到了positive PGR scaling,意味着随着student模型大小的增加,泛化能力得到了改善。
- ChatGPT Reward Modeling:相比之下,这一任务在泛化能力和缩放方面的表现都较差。即使增加student模型的大小,使用弱监督的student模型与使用真实标签训练的模型之间的性能差距也未能有效缩小。
实验还展示了不同强student模型大小对测试准确性的影响,并通过色彩编码展示了不同大小的弱监督者对强student准确性的影响。
提出的改进方法¶
很遗憾,这部分提出的方法都没法在所有的三个任务中很好得起作用,作者称之为“proofs-of-concept”的方法。也许这提供了个很好的进一步研究的机会,为什么提出的三个改进方法都只能在一个任务中起作用而在其他任务中不太起作用,进一步探究应该能获得比较有趣的结论。
Bootstrapping with intermediate model sizes¶
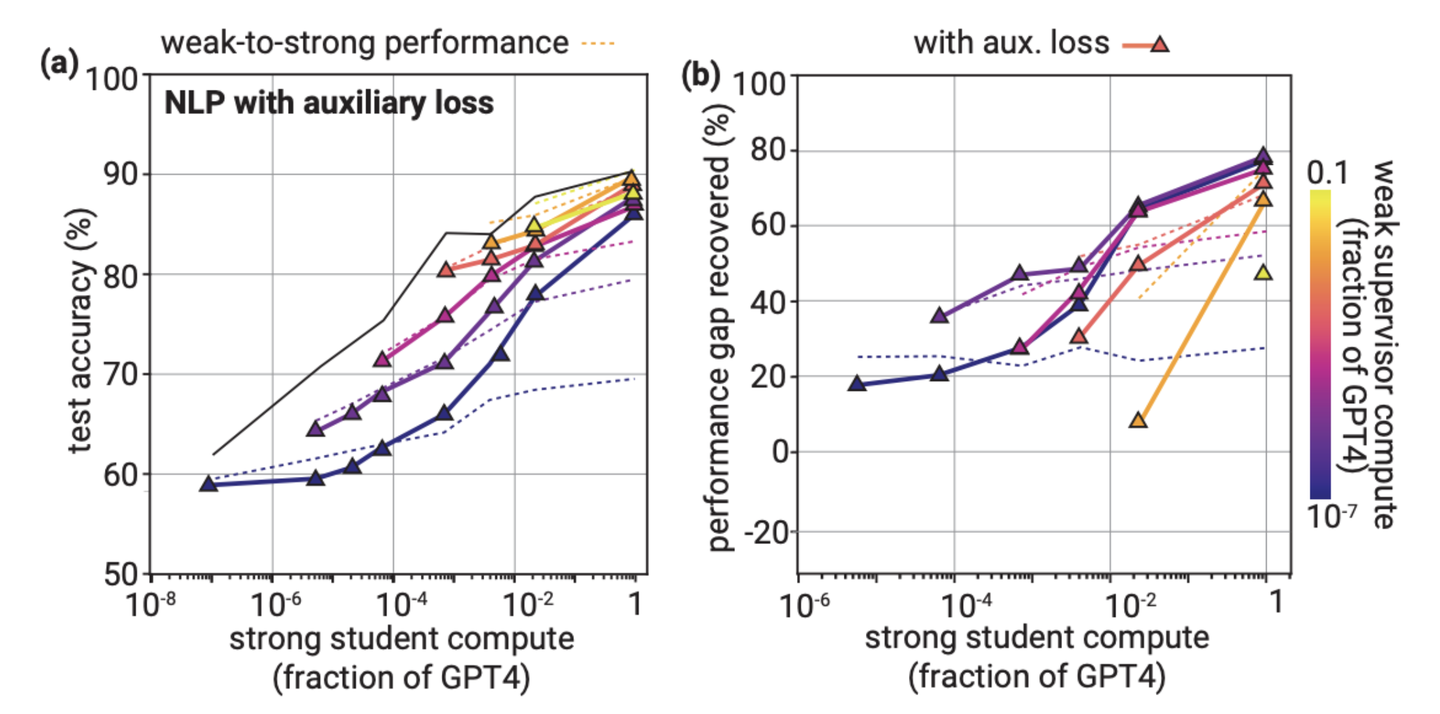
Bootstrapping改善chess puzzles表现
这一方法是在chess puzzles的setting下进行验证的。作者建立了一系列逐渐增大的模型,从 M_1 到 M_n,使用 M_1 的弱标签来微调 M_2,然后用 M_2 生成新的弱标签来微调下一个模型 M_3,依此类推。在chess puzzles的setting中,通过简单的weak labels微调,当supervisor-student之间的差距小的时候,性能差距恢复(PGR)表现良好;但当差距较大时,PGR就会降低。因此,在这种情况下,采取多个小step而不是一次性采取大step可能会更有帮助。
但这个方法在其他两个task里却不怎么work,其实直觉上比较好理解,因为traditional NLP和reward modeling里weak-to-strong是不怎么掉点的,顶多PGR是一个很小的证书,但是在chess puzzles任务里,如果weak和strong model的size差的比较大,那利用weak labels监督得到的strong model性能就退化的比较严重,因此这种bootstrapping的策略可以起作用。
An Auxiliary confidence loss¶
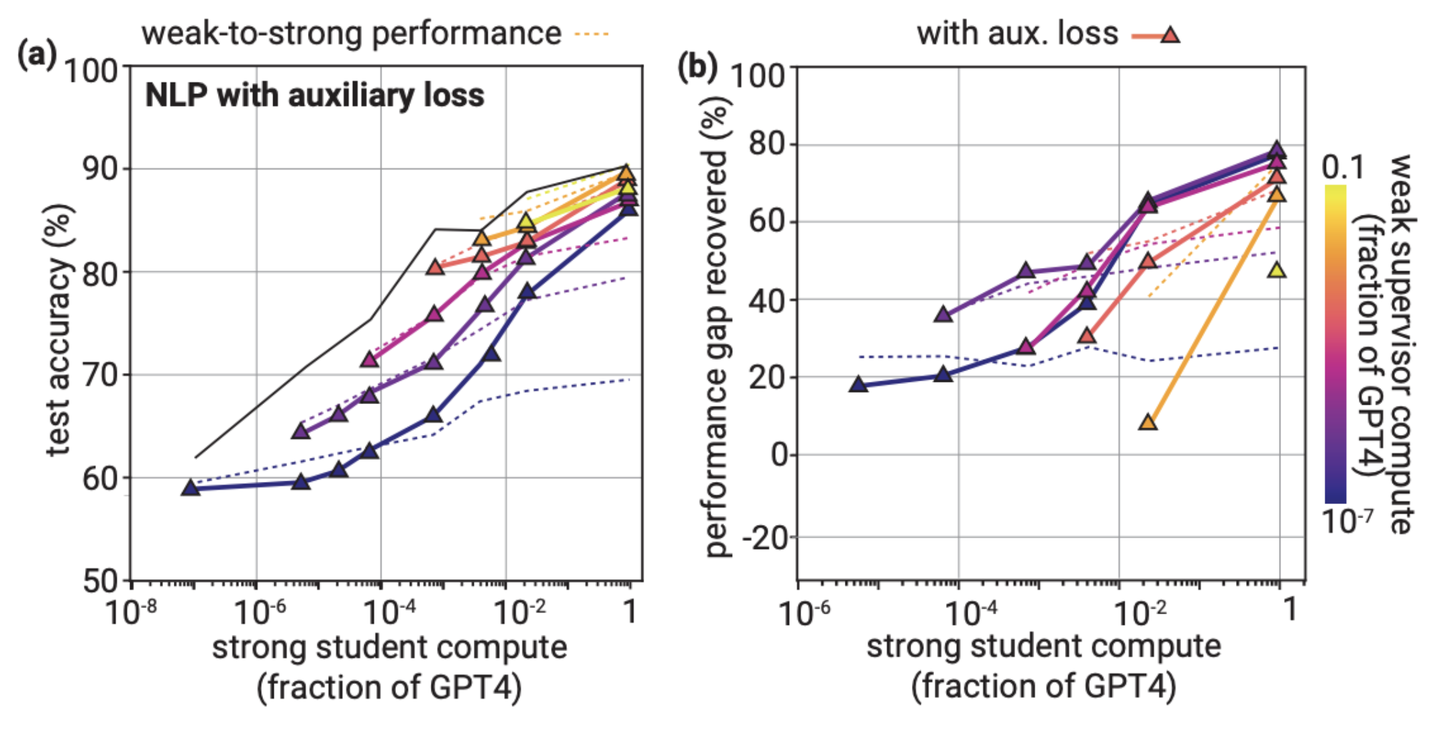
AUXILIARY CONFIDENCE LOSS改善NLP任务性能
其实听起来很高级,实际上就是添加一个有关confidence的正则项,用来增强strong model对其自身预测的confidence。因为weak supervisior提供的信息不怎么准确,可能有错误的label,但我们只想strong model去学正确的label,那么confidence低的sample可能就是wrong case,这个时候我们就不希望strong模型去拟合,所以说这个可以起作用。效果看上图。
然后论文又列举了一系列有关imitation的定量分析来理解strong model是如何从weak labels里学信息的,具体的就不展开了,感兴趣可以看原文。
3. 相关工作¶
首先是OpenAI自己在research direction提出的三个相关工作:
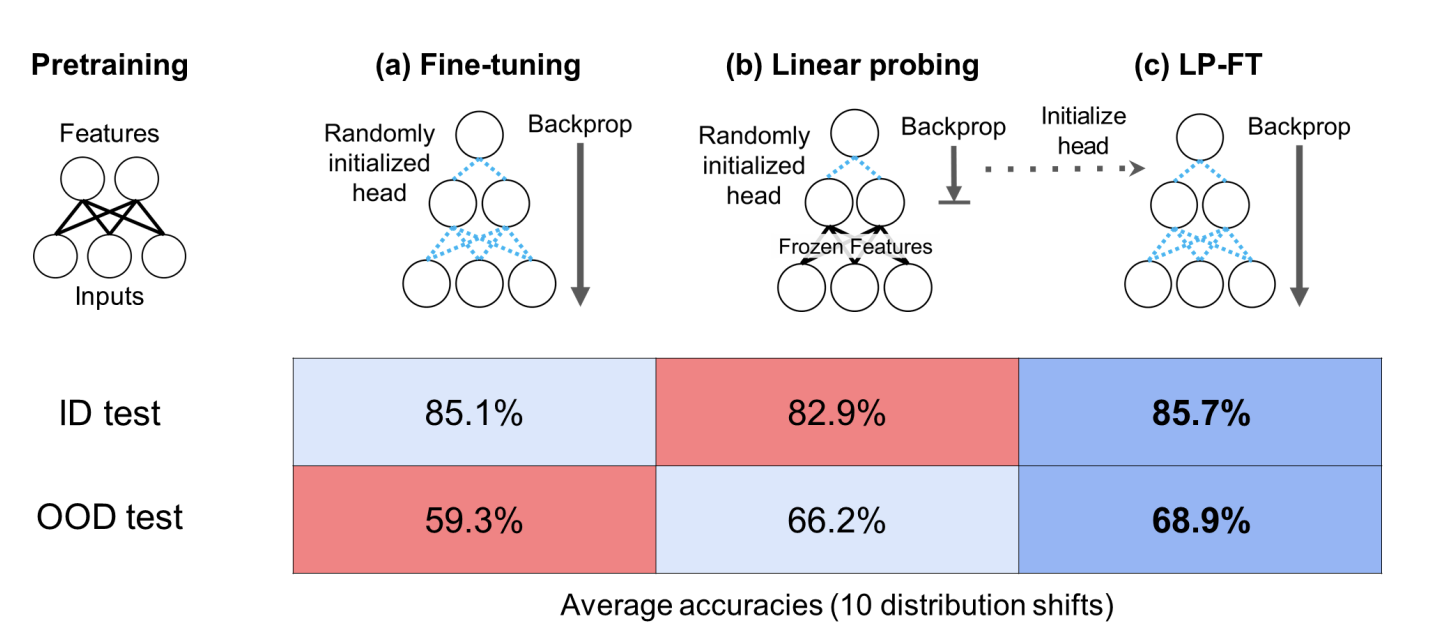
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
- Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution :Ananya这篇工作我觉得非常牛,几乎可以说是改变了我对于怎么fine-tuning的理解:在基于一个pretraining model在一个dataset上fine-tuning的时候feature fine-tuning和linear probing应该怎么选择,会对最后的ID和OOD结果造成什么影响。其实在和这个问题下,引申出来的一点就是,这种weak-to-strong的训练模式,会对模型的OOD test带来什么影响,比如weak labels里存在一些noise,是不是会导致strong model的OOD test变差。
- Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations :神经网络经常会依赖spurious features进行分类,那么weak supervisor和strong model之间的gap能否从这个层面来理解呢?所以是不是也可以考虑相应的训练技巧来缓解overfitting weak labels。
- Diversify and Disambiguate: Learning From Underspecified Data :Underspecified Data本身就比较契合weak labels的场景,因为通过weak supervisor获取的很多样本中,可能很多标注信息都是不可靠的,可能我们更需要的是充分利用weak supervisor的特征而不是不那么reliable的labels,而如何利用这些weak labels又是值得探索的。
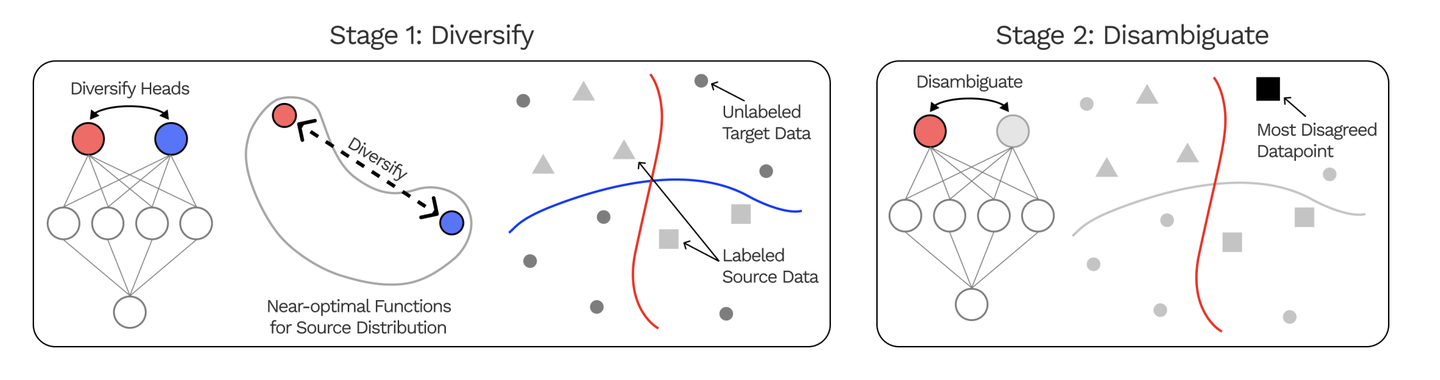
Diversify and Disambiguate: Learning From Underspecified Data
其它的工作也有采用类似的weak supervisor的思想(但不完全是follow OpenAI论文的setting),可能可以拓宽这个问题的应用场景:
Self-Play Fine-Tuning
- Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models :使LLM通过自我生成训练数据来自我提升,无需额外的人工标注数据,不断地完成从weak model到strong model的进化。
- Superfiltering: Weak-to-Strong Data Filtering for Fast Instruction-Tuning :利用Weak model来筛选出理想的data来用于fine-tuning strong model,从而加快SFT的效率。
- Aligner: Achieving Efficient Alignment through Weak-to-Strong Correction :通过学习对齐和未对齐答案之间的残差来绕过整个RLHF过程,实现了一种parameter-efficient的对齐解决方案。
4. Following idea¶
- Framework:虽然这篇论文很好得提供了一个pipeline来让我们“proofs-of-concept”得理解了weak-to-strong generalization这一技术,但是很OpenAI的是,论文并没有提供完整的相关实验的技术细节,包括训练的超参数和提供相应的pre-trained model(应该都是GPT家族的不同尺度的language model),所以reproduce出论文的结果也是非常有必要的。而且PGR虽然是一个很方便follow和理解的metric,但似乎还是太狭隘了,无法完全全面得评估出weak-to-strong generalization的性能和现象,比如为什么同一个trick在一个任务中能work另一个就不行?定量的实验比较会比定性的理解更有帮助。
- obustness and out-of-distribution generalization:PGR只是一个评估in-distribution性能的指标,而更大的language model显然要比更小的language model具有更强的out-of-distribution generalization能力,那么基于weak supervisor训练的strong model,它的out-of-distribution generalization会如何变化呢?是不是会显著得退化呢?如果是,怎么解决这一问题?
- Learning with noisy label: 显而易见,weak labels相较于ground truth肯定是充满噪声的,那么如何在这种noisy label中完成strong model的训练就是一个很有趣的topic了。另外weak label里的这些wrong cases和自然界存在的noise有什么区别和联系?能否直接采用传统ML里的noisy label的计较来直接。
- Data selection vs Training dynamic: 如果想基于weak labels训练出更好的strong model,那么是做weak dataset的清洗挑选更重要呢,还是改进训练的方法更关键呢?
- Weak samples trade-off : 更多的数据对训练来说肯定是更有帮助的,但是有一部分数据可能是不太可靠的,如果直接训练的时候所有的unreliable data都不利用,会出现什么样的现象?
- Reward modeling:为什么相较于其它两个任务,Reward modeling的weak-to-strong generalization表现就这么差劲,而且提出的两个改进方法在RM也都没什么明显的改善?这一任务和其他任务有什么不同?
- LLM alignment:RLHF还是现在主要的alignment的方法,其中重要的一步就是基于preference来训练reward model。但是人与人之间的preference本身就是不一致的,现在应用最为广泛的HH-RLHF 这一数据集,Researcher-Crowdworker Agreement都仅有63%左右,也就说明这种preference datasets某种程度上也可以视为一种“weak labels”,如果我们找到了一种可以改善weak-to-strong generalization的方法,那么基于此是否我们就能获得superhuman的reward model用于更好地完成RLHF呢?
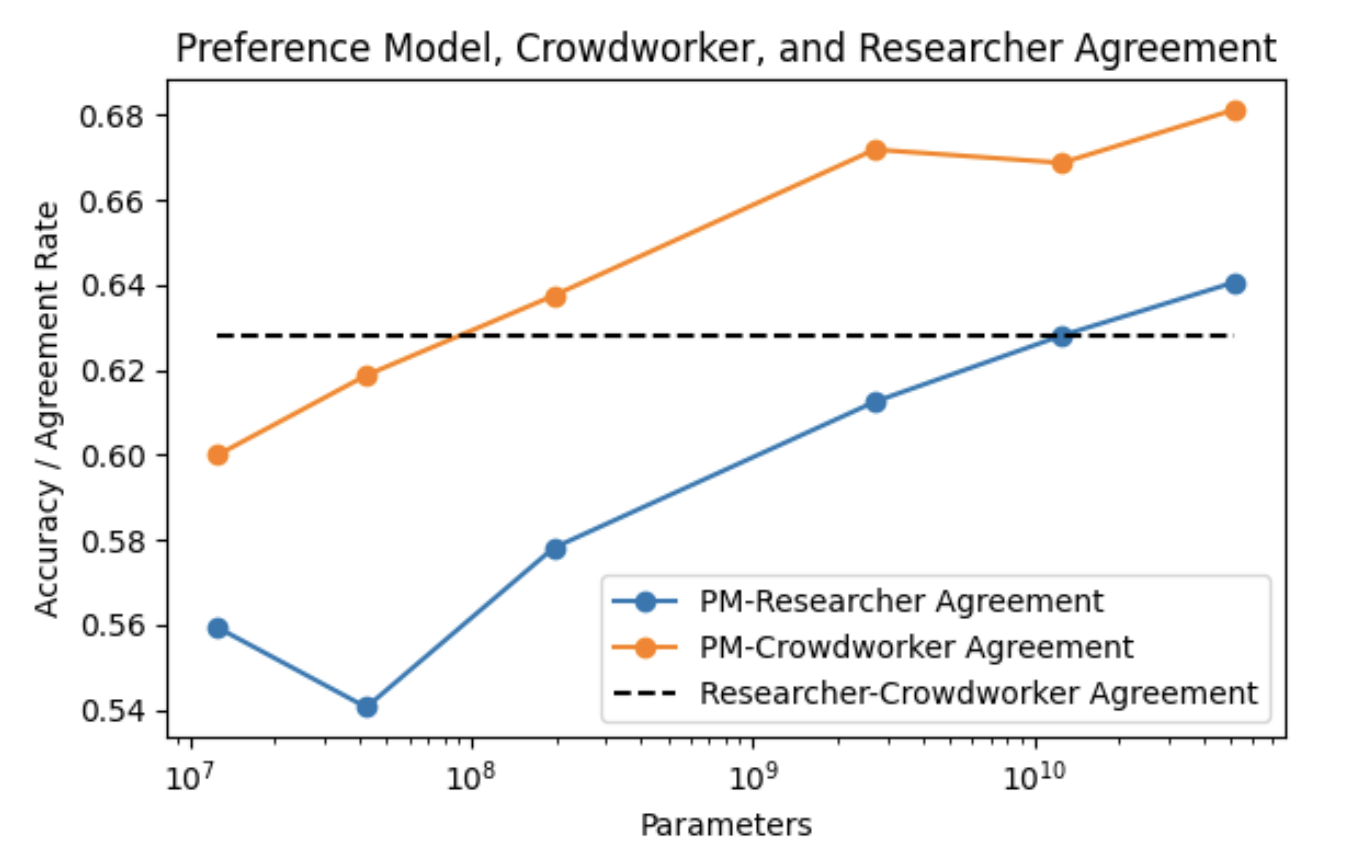
HH-RLHF数据集的performance
- Learning theory:得到的weak labels中有非常多的noise,也就是information-theoretically来说,weak-to-strong要做的就是hack noise,从learning theory的角度来讲怎么解决?
本人只是一个LLM入门的新手小菜鸡,如有谬误请各位批评和指正。如果对这个topic感兴趣也欢迎私戳讨论啊。
本文总阅读量次