【CV中的Attention机制】ShuffleAttention¶
【GiantPandaCV导语】这个系列已经好几个月没有更新了,开始继续更这个方向论文,19年、20年又出现了很多关于Attention的研究,本文SA-Net:shuffle attention for deep convolutional neural networks 发表在ICASSP 21,传承了SGE的设计理念的同时,引入Channel Shuffle,达到了比较好的效果,有理有据。文章首发于GiantPandaCV,请勿二次转载。
1. 摘要¶
目前注意力机制主要可以分为两类,空间注意力机制和通道注意力机制,两者目标用于捕获成对的像素级关系和通道间依赖关系的。同时使用两种注意力机制可以达到更好的效果,但是不可避免地增加了模型的计算量。
本文提出了Shuffle Attention(SA)模块来解决这个问题,可以高效地结合两种注意力机制。具体来讲:
- SA对通道特征进行分组,得到多个组的子特征。
- 对每个子特征使用SA Unit同时使用空间和通道间注意力机制。
- 最后,所有的子特征会被汇集起来,然后使用Channel Shuffle操作让不同组的特征进行融合。
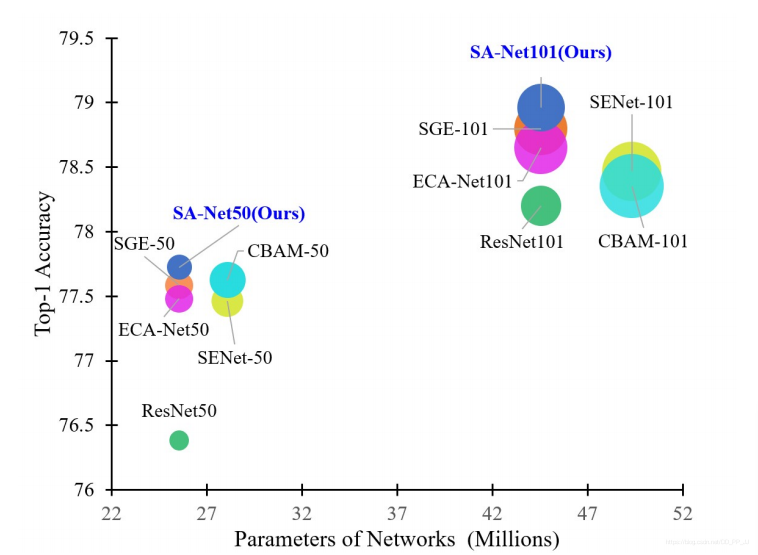
实验结果:在ImageNet-1k数据集上,SA结果要比ResNet50的top 1高出1.34%。同时在MS COCO数据集上进行了目标检测和目标分割的实验,在模型复杂度比较低的情况下,达到了SOTA。
这个实验思路可以看出和SENet如出一辙,分组处理的思想在SGE中提到过,SA-Net添加了Channel Shuffle的操作参考ShuffleNet系列论文,有理有据,实现也很简单。
2. 设计思想¶
多分支结构
多分支结构比如最初的InceptionNet系列、ResNet系列等都是多分支结构,遵从的是‘Split - Transform - Merge’的操作模式,这样的设计可以让模型变得更深、更易于训练。
Attention 模块的设计方面也有很多工作引入了多分支,比如SKNet、ResNeSt、SGENet等。
组特征
最初将特征划分为不同的组可以追溯到AlexNet,由于当时的显存太小,所以需要将模型分成两组,每组使用一块显卡进行处理,这是为了解决使用更多计算资源的问题。
之后的MobileNet系列、ShuffleNet系列等使用组特征是为了降低模型的计算量,加快运算速度。
CapsuleNet则是将每个组的神经元视为一个胶囊Capsule,其中,激活的胶囊中的神经元活动代表了图像中特定实体的各种属性。
注意力机制
注意力模块已经成为网络设计的不得不考虑的重要组成部分。注意力模块可以有侧重点的关注有用的特征信息,抑制不重要的特征。self-attention方法是计算一个位置和其上下文的信息作为一个权重,施加到整个图像中。SE对通道间关系进行建模,使用了两个全链接网络进行自学习。ECA则使用了1-D卷积来生成通道间注意力机制,降低了SE的计算量。CBAM,GCNet,SGE等模型结合了空间注意力机制和通道注意力机制。DANet通过将来自不同分支的两个注意模块相加,自适应地整合了局部特征及其全局依赖关系
3. Shuffle Attention¶
SA的设计思想结合了组卷积(为了降低计算量),空间注意力机制(使用GN实现),通道注意力机制(类似SENet),ShuffleNetV2(使用Channel Shuffle融合不同组之间的信息)。
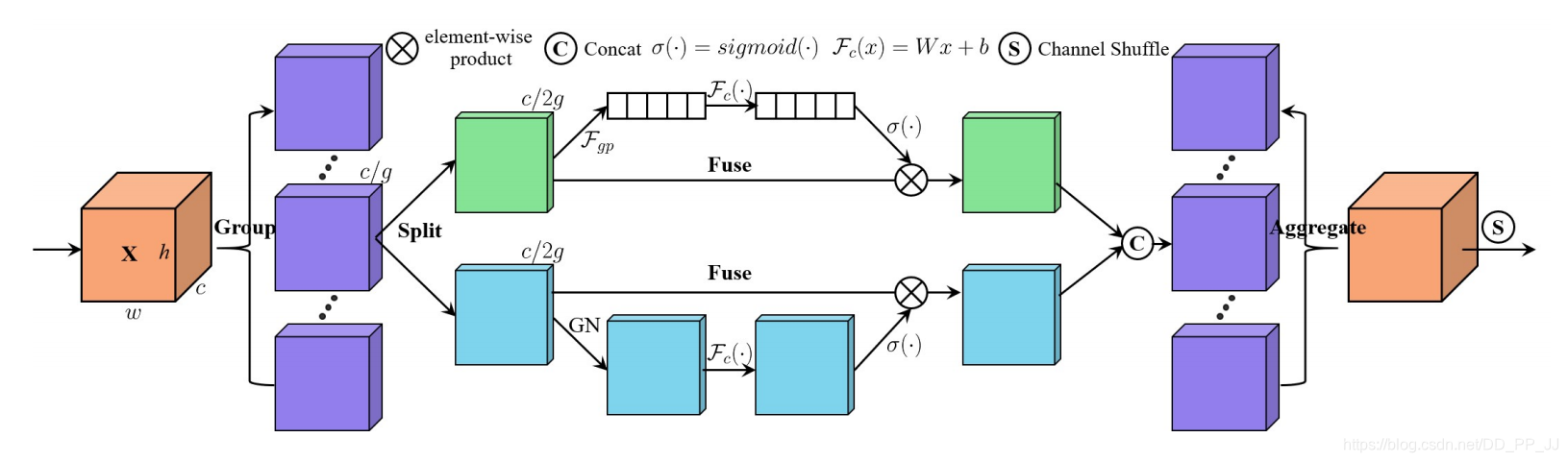
如上图所示:
- 首先将tensor划分为g个组,每个组内部使用SA Unit进行处理。
- SA内部分为空间注意力机制,如蓝色部分所示,具体实现使用的是GN。
- SA内部使用的通道注意力机制,如绿色部分所示,具体实现和SE类似。
- SA Unit通过Concate的方式将组内部的信息进行融合。
- 最后使用Channel Shuffle操作对组进行重排,不同组之间进行信息流通。
GN实现的空间注意力
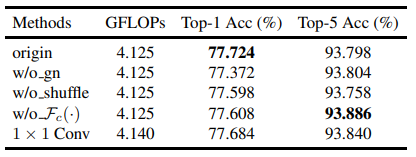
一般来说,空间注意力机制作用是找到图片中具体哪一块更重要。SA中使用了GroupNorm来获取空间维度的信息。这部分比较特别,但是作者通过消融实验证明了该模块有效性。或许有更好的Spatial Attention?毕竟也没有比较类似CBAM的这种空间注意力方法,所以并不知道GN作为空间注意力是否有优越性。

4. 实验结果¶
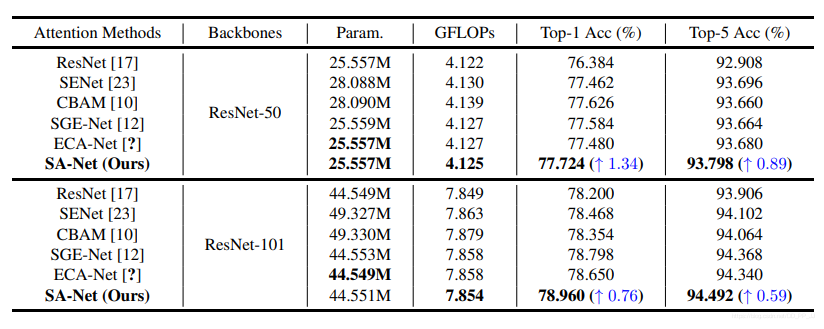
可以看到,要比ECA-Net等模型效果更好,并且要比baseline ResNet50的top1高出1.34%。同样的在ResNet-101为基础添加SA模块,也要比baseline 的top1要高出了0.76%。
目标检测上的实验对比:
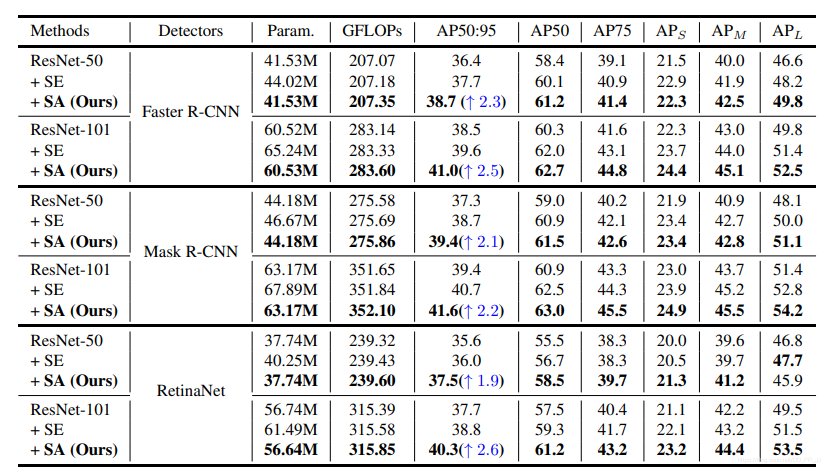
可以看出实验提升还是比较大的,AP大约提升了2-3个百分点。
实例分割任务上的实验结果对比:

5. 结论¶
SA是的核心思想都有迹可循,通过引入组卷积降低计算量,再对每个分组使用空间注意力和通道注意力,最后使用Channel Shuffle操作将不同组之间的信息进行流通。
6. 参考¶
代码链接:https://github.com/wofmanaf/SA-Net
论文链接:https://arxiv.org/pdf/2102.00240.pdf
本文总阅读量次