NCNN+Int8+yolov5部署和量化
本文版权属于GiantPandaCV,未经允许请勿转载
前言: 还记得我在两个月前写的文章吗,关于yolov4-tiny+ncnn+int8量化的详细教程: https://zhuanlan.zhihu.com/p/372278785
后来准备写yolov5+ncnn+int8量化的教程,却在yolov5的量化上遇到了麻烦,一方面是量化后速度更慢了,另一方面是精度下降严重,出现满屏都是检测框的现象,后来经过很多尝试,最终都以失败告终。
再后来,还是决定换其他方式对yolov5进行量化,一是即使最小的yolov5s模型量化后能提速,依旧满足不了我对速度的需求,二是对于Focus层,不管使用哪个向前推理框架,要额外添加对Focus层的拼接操作对我来说过于繁琐。
于是,我对yolov5做了一系列轻量化的改动,让他网络结构更加简洁,也能够实打实的提速(例如arm架构系列的树莓派,至少能提速三倍;x86架构的inter处理器也能提速一倍左右):
模型结构详见:https://zhuanlan.zhihu.com/p/400545131
这篇博客,还是接着上一篇yolov4量化的工作,对yolov5进行ncnn的部署和量化。
一、环境准备¶
主要需要的工具有两样:
ncnn推理框架 地址链接:https://github.com/Tencent/ncnn
shufflev2-yolov5的源码和权重
地址链接:https://github.com/ppogg/shufflev2-yolov5
模型性能如下:


关于ncnn的编译和安装,网上的教程很多,但是推荐在linux环境下运行,window也可以,但可能踩的坑比较多。
二、onnx模型提取¶
git clone https://github.com/ppogg/shufflev2-yolov5.git
python models/export.py --weights weights/yolov5ss.pt --img 640 --batch 1
python -m onnxsim weights/yolov5ss.onnx weights/yolov5ss-sim.onnx
这过程一般都很顺利~

三、转化为ncnn模型¶
./onnx2ncnn yolov5ss-sim.onnx yolov5ss.param yolov5ss.bin
./ncnnoptimize yolov5ss.param yolov5ss.bin yolov5ss-opt.param yolov5ss-opt.bin 65536
这个过程依旧不会卡点,很顺利就提取完了,此时就有包含fp32,fp16,一共是4个模型:

为了实现动态尺寸图片处理,需要对yolov5ss-opt.param的reshape操作进行修改:

把以上三处reshape的尺度统统改成-1:

其他地方无需改动。
四、后处理修改¶
ncnn官方的yolov5.cpp需要修改两处地方
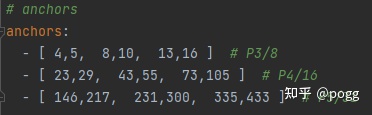
anchor信息是在 models/yolov5ss-1.0.yaml,需要根据自己的数据集聚类后的anchor进行对应的修改:
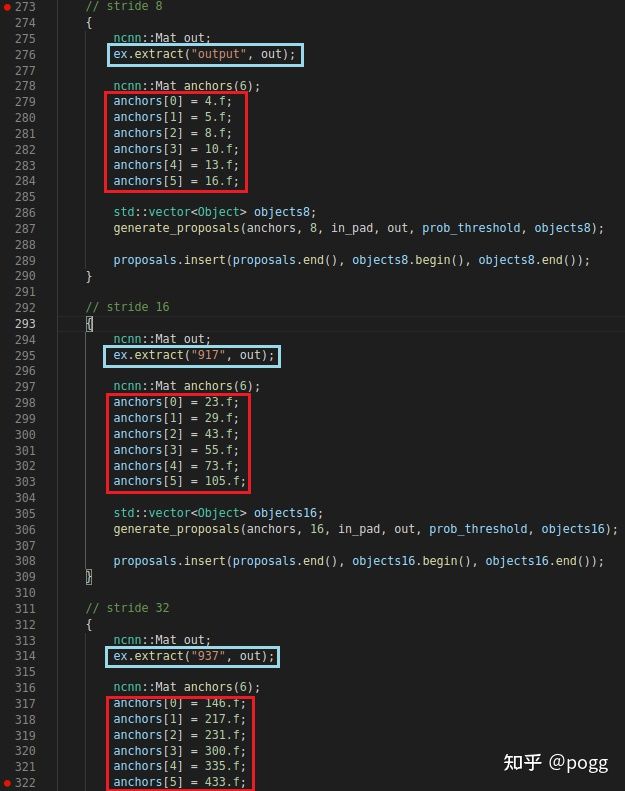
输出层ID在Permute层里边,也需要进行相应的修改:

修改后如下:
此时,修改的地方只有以上几点,Focus层代码也可看个人情况移除,重新make就可以进行检测。
fp16的模型检测效果如下:

还有,不要再问为什么三轮车检测不出来了。。你家coco数据集有三轮车是吗。。

五、Int8量化¶
更加详细的教程可以参考本人知乎博客关于yolov4-tiny的教程,很多细节的东西本篇不会累述(下方附链接)。
这里需要补充几点:
- 校验表数据集请使用coco_val那5000张数据集;
- mean和val的数值需要和原先自己训练模型时候设定的数值保持一致,在yolov5ss.cpp里也
需要保持一致;
- 校验过程比较漫长,请耐心等候
运行代码:
find images/ -type f > imagelist.txt
./ncnn2table yolov5ss-opt.param yolov5ss-opt.bin imagelist.txt yolov5ss.table mean=[104,117,123] norm=[0.017,0.017,0.017] shape=[640,640,3] pixel=BGR thread=8 method=kl
./ncnn2int8 yolov5ss-opt.param yolov5ss-opt.bin yolov5ss-opt-int8.param yolov5ss-opt-int8.bin yolov5ss.table
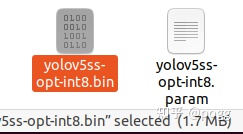
量化后的模型大小大概在1.7m左右,应该可以满足你对小模型大小的强迫症;
此时,可以使用量化后的shufflev2-yolov5模型进行检测:

量化后的精度略有损失,但还是在可接受范围内。模型在量化后不可能精度完全不下降,对于大尺度特征明显的目标,shufflev2-yolov5对此类目标的score可以保持不变(其实还是会下降一丢丢),但对于远距离的小尺度目标,score会下降10%-30%不等,没办法的事,所以请理性看待该模型。
除去前三次预热,树莓派温度温度在45°以上,对模型进行测试,量化后的benchmark如下:
# 第四次
pi@raspberrypi:~/Downloads/ncnn/build/benchmark $ ./benchncnn 8 4 0
loop_count = 8
num_threads = 4
powersave = 0
gpu_device = -1
cooling_down = 1
shufflev2-yolov5 min = 90.86 max = 93.53 avg = 91.56
shufflev2-yolov5-int8 min = 83.15 max = 84.17 avg = 83.65
shufflev2-yolov5-416 min = 154.51 max = 155.59 avg = 155.09
yolov4-tiny min = 298.94 max = 302.47 avg = 300.69
nanodet_m min = 86.19 max = 142.79 avg = 99.61
squeezenet min = 59.89 max = 60.75 avg = 60.41
squeezenet_int8 min = 50.26 max = 51.31 avg = 50.75
mobilenet min = 73.52 max = 74.75 avg = 74.05
mobilenet_int8 min = 40.48 max = 40.73 avg = 40.63
mobilenet_v2 min = 72.87 max = 73.95 avg = 73.31
mobilenet_v3 min = 57.90 max = 58.74 avg = 58.34
shufflenet min = 40.67 max = 41.53 avg = 41.15
shufflenet_v2 min = 30.52 max = 31.29 avg = 30.88
mnasnet min = 62.37 max = 62.76 avg = 62.56
proxylessnasnet min = 62.83 max = 64.70 avg = 63.90
efficientnet_b0 min = 94.83 max = 95.86 avg = 95.35
efficientnetv2_b0 min = 103.83 max = 105.30 avg = 104.74
regnety_400m min = 76.88 max = 78.28 avg = 77.46
blazeface min = 13.99 max = 21.03 avg = 15.37
googlenet min = 144.73 max = 145.86 avg = 145.19
googlenet_int8 min = 123.08 max = 124.83 avg = 123.96
resnet18 min = 181.74 max = 183.07 avg = 182.37
resnet18_int8 min = 103.28 max = 105.02 avg = 104.17
alexnet min = 162.79 max = 164.04 avg = 163.29
vgg16 min = 867.76 max = 911.79 avg = 889.88
vgg16_int8 min = 466.74 max = 469.51 avg = 468.15
resnet50 min = 333.28 max = 338.97 avg = 335.71
resnet50_int8 min = 239.71 max = 243.73 avg = 242.54
squeezenet_ssd min = 179.55 max = 181.33 avg = 180.74
squeezenet_ssd_int8 min = 131.71 max = 133.34 avg = 132.54
mobilenet_ssd min = 151.74 max = 152.67 avg = 152.32
mobilenet_ssd_int8 min = 85.51 max = 86.19 avg = 85.77
mobilenet_yolo min = 327.67 max = 332.85 avg = 330.36
mobilenetv2_yolov3 min = 221.17 max = 224.84 avg = 222.60
至于之前的yolov5s为什么量化后速度变慢,甚至精度下降严重,唯一的解释就出在了Focus层,这玩意稍微对不齐就很容易崩,也比较费脑,索性移除了。
总结:¶
- 本文提出shufflev2-yolov5的部署和量化教程;
- 剖析了之前yolov5s之所以量化容易崩坏的原因;
- ncnn的fp16模型对比原生torch模型精度可保持不变;

[上图,左为torch原模型,右为fp16模型]
- ncnn的int8模型精度会略微下降,速度在树莓派上仅能提升5-10%,其他板子暂未测试;

[上图,左为torch原模型,右为int8模型]
项目地址:https://github.com/ppogg/shufflev2-yolov5
欢迎star和fork~
2021年08月20日更新: ----------------------------------------------------------
本人已经完成了Android版本的适配
这是本人的红米手机,处理器为高通骁龙730G,检测的效果如下:
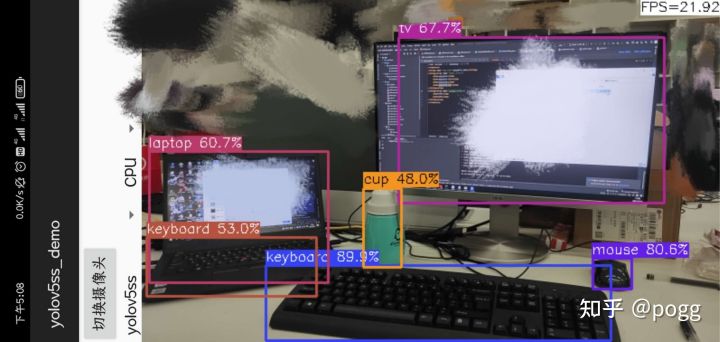
这是量化后的int8模型检测效果:

户外场景检测:

参考:
【1】nihui:详细记录u版YOLOv5目标检测ncnn实现
【2】pogg:NCNN+Int8+YOLOv4量化模型和实时推理
【3】pogg:ncnn+opencv+yolov5调用摄像头进行检测
【4】https://github.com/ultralytics/yolov5
本文总阅读量次