1. 前言¶
三值化网络是2016年由Fengfu Li在论文《Ternary Weight Networks》中提出来的,它相比二值化网络具有更好的效果。论文地址如下:https://arxiv.org/abs/1605.04711 。
2. 出发点¶
首先,论文提出多权值比二值化具有更好的网络泛化能力。论文中提到,在VGG,GoogLeNet 和残留网络等最新的网络体系结构中,最常用的卷积滤波器大小为3\times 3,如果使用上一节提到的二值权重,有2^{3\times 3}=512个模板,但如果使用三值权重就有3^{3\times 3}=19683个模板,它的表达能力比二值权重强很多。
另外,在TWN中,每一个权重单元只需要2字节的存储空间。因此,和浮点数相比,TWN实现了高达16倍的模型压缩率。在计算能力方面,和二值化网络相比,TWN拥有额外的零值,但是零值不增加任何的乘法运算。因此,TWN中的乘法累加操作次数和二值化网络相比保持不变。
3. 三值化网络的原理¶
3.1 问题引入¶
首先,论文认为权值的分布接近于一个正态分布和一个均匀分布的组合。然后,论文提出使用一个scale参数去最小化三值化前的权值和三值化之后的权值的L2距离。
参数三值化的公式如下:
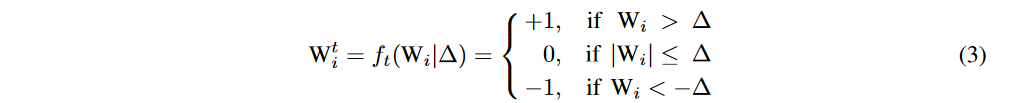
即我们选取一个阈值\Delta,大于这个阈值的权重就变成1,小于这个阈值的权重就变成-1,中间的为0。然后这个阈值是根据权重分布的先验知识计算出来的。这篇论文最核心的部分就是阈值和scale参数alpha的推导过程。
在参数三值化后,论文使用了一个scale参数(用\alpha表示)让三值化后的参数更接近三值化之前的参数,具体如下:
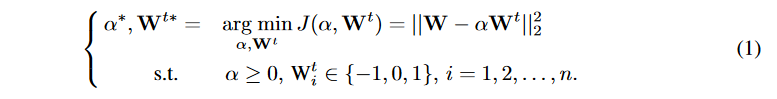
其中,n表示卷积核的数量,权重估计W\approx \alpha W^t。
然后,三值网络的前向传播过程如下:
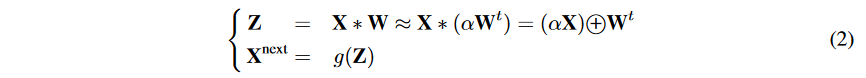
其中,X是输入的矩阵块,*是卷积运算或者内积运算,g是非线性激活函数,\bigoplus是积或卷积运算,无任何乘法。X^{next}是输出的矩阵块。
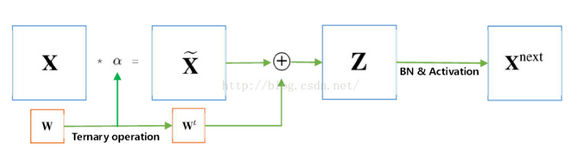
可以看到,在把\alpha乘到前面以后,我们就可以把复杂的乘法运算变成了简单的加法运算,从而加快了整个训练速度。
3.2 基于阈值的三值函数近似解¶
现在我们的目标是求解等式(1),然后我们容易知道上面的等式不仅仅和\alpha有关,还和W^t有关,而W^t是根据等式三来控制的,即:
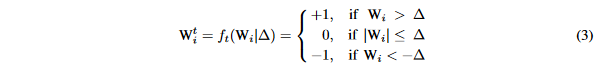
给定一个\Delta就能确定一组W参数,有了等式(3)之后原始的问题即等价于:
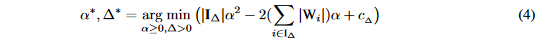
其中I_{\Delta}={i||W_i|>\Delta}并且|I_{\Delta}|表示在I_{\Delta}里面的元素个数。c_{\Delta}=\sum_{i\in I_{\Delta}^c}W_i^2是一个只和\alpha有关的一个独立常量。因此,对于任意的给定的\Delta,可选参数\alpha可以表示为如下式子:
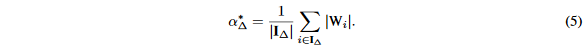
通过将\alpha_{\Delta}^*带入到等式4中,我们获得了一个\Delta独立的等式,可以表示为:

由于这个式子需要迭代才能得到解(即不断的调\Delta和\alpha),会造成训练速度过慢,所以如果可以提前预测权重的分布,就可以通过权重分布大大减少阈值计算的计算量。文中推导了正态分布和平均分布两种情况,并按照权值分布式正态分布和平均分布的组合的先验知识提出了计算阈值的经验公式,即:
\Delta^*\approx 0.7*(|W|)\approx \frac{0.7}{n}\sum_{i=1}^n|W_i|
4. 代码实战¶
仍然使用上次提到的Github工程的代码来分析。地址为:https://github.com/666DZY666/model-compression
4.1 定义网络结构¶
注意这个网络结构里面有一个channel_shuffle的操作,这是旷视的 添加卷积神经网络学习路线(十九) | 旷世科技 2017 ShuffleNetV1
提出的。然后剩下的代码就是在搭建一个三值化网络,这里的核心实现在Conv2d_Q中。
import torch.nn as nn
from .util_wt_bab import activation_bin, Conv2d_Q
# 通道混合
def channel_shuffle(x, groups):
"""shuffle channels of a 4-D Tensor"""
batch_size, channels, height, width = x.size()
assert channels % groups == 0
channels_per_group = channels // groups
# split into groups
x = x.view(batch_size, groups, channels_per_group, height, width)
# transpose 1, 2 axis
x = x.transpose(1, 2).contiguous()
# reshape into orignal
x = x.view(batch_size, channels, height, width)
return x
# ********************* 量化(三/二值)模块 ************************
class Tnn_Bin_Conv2d(nn.Module):
# 参数:groups-卷积分组数、channel_shuffle-通道混合标志、shuffle_groups-通道混合数(本层需与上一层分组数保持一致)、last_relu|last_bin-尾层卷积输入是否二值(二值:last_relu=0,last_bin=1)
def __init__(self, input_channels, output_channels,
kernel_size=-1, stride=-1, padding=-1, groups=1, channel_shuffle=0, shuffle_groups=1, A=2, W=2, last_relu=0, last_bin=0):
super(Tnn_Bin_Conv2d, self).__init__()
self.channel_shuffle_flag = channel_shuffle
self.shuffle_groups = shuffle_groups
self.last_relu = last_relu
self.last_bin = last_bin
# ********************* 量化(三/二值)卷积 *********************
self.tnn_bin_conv = Conv2d_Q(input_channels, output_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, A=A, W=W)
self.bn = nn.BatchNorm2d(output_channels)
self.relu = nn.ReLU(inplace=True)
self.bin_a = activation_bin(A=A)
def forward(self, x):
if self.channel_shuffle_flag:
x = channel_shuffle(x, groups=self.shuffle_groups)
x = self.tnn_bin_conv(x)
x = self.bn(x)
if self.last_relu:
x = self.relu(x)
if self.last_bin:
x = self.bin_a(x)
return x
class Net(nn.Module):
def __init__(self, cfg = None, A=2, W=2):
super(Net, self).__init__()
# 模型结构与搭建
if cfg is None:
cfg = [256, 256, 256, 512, 512, 512, 1024, 1024]
self.tnn_bin = nn.Sequential(
nn.Conv2d(3, cfg[0], kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(cfg[0]),
Tnn_Bin_Conv2d(cfg[0], cfg[1], kernel_size=1, stride=1, padding=0, groups=2, channel_shuffle=0, A=A, W=W),
Tnn_Bin_Conv2d(cfg[1], cfg[2], kernel_size=1, stride=1, padding=0, groups=2, channel_shuffle=1, shuffle_groups=2, A=A, W=W),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
Tnn_Bin_Conv2d(cfg[2], cfg[3], kernel_size=3, stride=1, padding=1, groups=16, channel_shuffle=1, shuffle_groups=2, A=A, W=W),
Tnn_Bin_Conv2d(cfg[3], cfg[4], kernel_size=1, stride=1, padding=0, groups=4, channel_shuffle=1, shuffle_groups=16, A=A, W=W),
Tnn_Bin_Conv2d(cfg[4], cfg[5], kernel_size=1, stride=1, padding=0, groups=4, channel_shuffle=1, shuffle_groups=4, A=A, W=W),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
Tnn_Bin_Conv2d(cfg[5], cfg[6], kernel_size=3, stride=1, padding=1, groups=32, channel_shuffle=1, shuffle_groups=4, A=A, W=W),
Tnn_Bin_Conv2d(cfg[6], cfg[7], kernel_size=1, stride=1, padding=0, groups=8, channel_shuffle=1, shuffle_groups=32, A=A, W=W, last_relu=0, last_bin=1),#二值量化:last_relu=0, last_bin=1;全精度:last_relu=1, last_bin=0
nn.Conv2d(cfg[7], 10, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(10),
nn.ReLU(inplace=True),
nn.AvgPool2d(kernel_size=8, stride=1, padding=0),
)
# 模型运行
def forward(self, x):
x = self.tnn_bin(x)
x = x.view(x.size(0), -1)
return x
4.2 TWN核心代码实现¶
TWN的核心代码实现如下:
# ********************* 三值(+-1、0) ***********************
class Ternary(Function):
@staticmethod
def forward(self, input):
# **************** channel级 - E(|W|) ****************
E = torch.mean(torch.abs(input), (3, 2, 1), keepdim=True)
# **************** 阈值 ****************
threshold = E * 0.7
# ************** W —— +-1、0 **************
output = torch.sign(torch.add(torch.sign(torch.add(input, threshold)),torch.sign(torch.add(input, -threshold))))
return output, threshold
@staticmethod
def backward(self, grad_output, grad_threshold):
#*******************ste*********************
grad_input = grad_output.clone()
return grad_input
# ********************* W(模型参数)量化(三/二值) ***********************
def meancenter_clampConvParams(w):
mean = w.data.mean(1, keepdim=True)
w.data.sub(mean) # W中心化(C方向)
w.data.clamp(-1.0, 1.0) # W截断
return w
class weight_tnn_bin(nn.Module):
def __init__(self, W):
super().__init__()
self.W = W
def binary(self, input):
output = Binary_w.apply(input)
return output
def ternary(self, input):
output = Ternary.apply(input)
return output
def forward(self, input):
if self.W == 2 or self.W == 3:
# **************************************** W二值 *****************************************
if self.W == 2:
output = meancenter_clampConvParams(input) # W中心化+截断
# **************** channel级 - E(|W|) ****************
E = torch.mean(torch.abs(output), (3, 2, 1), keepdim=True)
# **************** α(缩放因子) ****************
alpha = E
# ************** W —— +-1 **************
output = self.binary(output)
# ************** W * α **************
output = output * alpha # 若不需要α(缩放因子),注释掉即可
# **************************************** W三值 *****************************************
elif self.W == 3:
output_fp = input.clone()
# ************** W —— +-1、0 **************
output, threshold = self.ternary(input)
# **************** α(缩放因子) ****************
output_abs = torch.abs(output_fp)
mask_le = output_abs.le(threshold)
mask_gt = output_abs.gt(threshold)
output_abs[mask_le] = 0
output_abs_th = output_abs.clone()
output_abs_th_sum = torch.sum(output_abs_th, (3, 2, 1), keepdim=True)
mask_gt_sum = torch.sum(mask_gt, (3, 2, 1), keepdim=True).float()
alpha = output_abs_th_sum / mask_gt_sum # α(缩放因子)
# *************** W * α ****************
output = output * alpha # 若不需要α(缩放因子),注释掉即可
else:
output = input
return output
可以看到\Delta参数直接使用了先验知识进行计算,然后利用\Delta和公式(5)计算出scale参数\alpha就完成了CNN权重的三值化。
5. 实验结果¶
下面看一下使用TWN在Cifar10上的测试结果,如下:
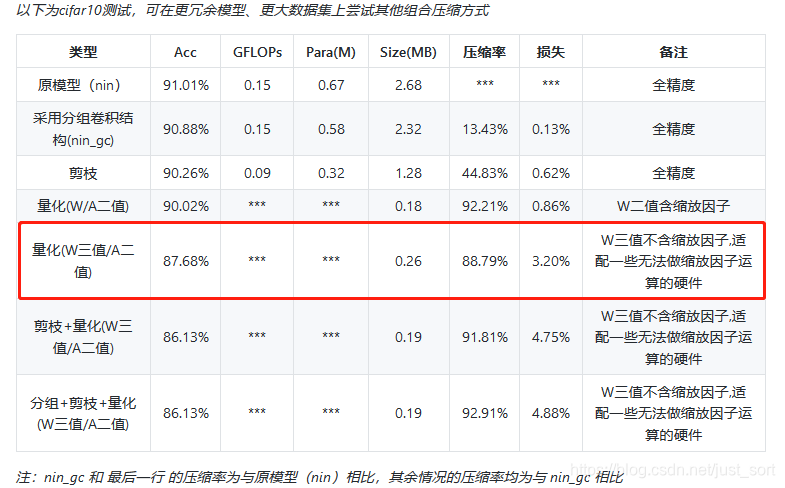
注意到这里使用了三值量化权值之后准确率比二值量化更低了,猜测是因为没有启用scale参数的原因。另外,这一组实验激活值是选用了二值化方法,论文中没有明确提到使用了哪种激活函数所以这里也是值得商榷的。下面再给一个论文中的实验结果。
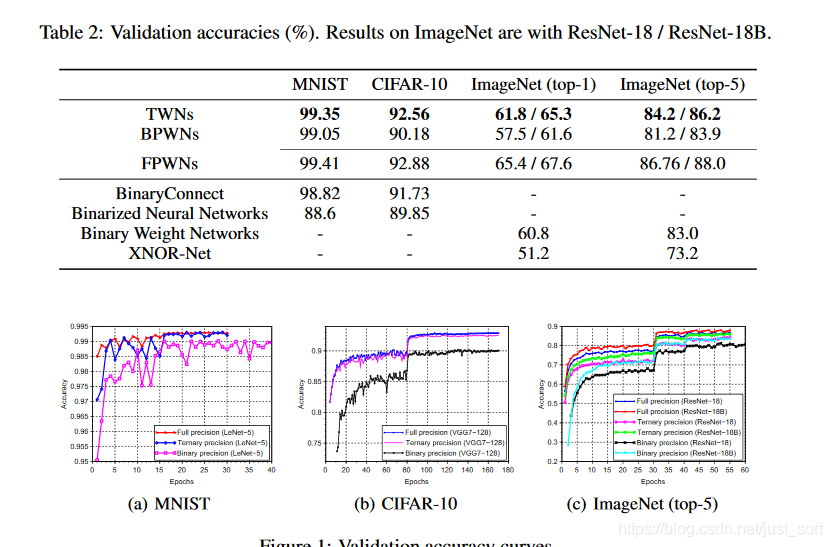
6. 总结¶
这篇文章主要是介绍了一下TWN这种方法的原理以及结合代码对其理解了一下,三值化的目的即是为了解决二值化网络表达能力不够的问题。然后这篇论文提供了一个比较好的思路,我们可以将这种方法进行推广,例如将权值组合变成(-2,-1,0,1,2),以期获得更高的准确率。另外值得一提的是权值三值化并没有完全消除乘法器,在实际进行前向传播的时候,它需要给每一个输出乘以scale参数,然后这个时候的权值是(-1,0,1),以此来减少乘法器的数目。
7. 参考¶
- 《深入移动平台性能优化》书籍
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次