微软亚洲研究院最新工作DeepMIM-MIM中引入深度监督方法
微软亚洲研究院最新工作|DeepMIM:MIM中引入深度监督方法¶
解读:Freedom
Paper title: DeepMIM: Deep Supervision for Masked Image Modeling
Arxiv Link: https://arxiv.org/pdf/2303.08817.pdf
Code: https://github.com/OliverRensu/DeepMIM.
主要解决的问题¶
DeepMIM旨在网络的浅层加入额外的监督,使得浅层特征的学习更有意义。所提的 DeepMIM 则使用了深度监督学习来提高图像重建的准确性和鲁棒性,使得模型可以自适应地学习图像重建的规律和特征,从而可以更快速、更准确地完成重建任务。此外,DeepMIM 与许多用于重建目标的 MIM 模型兼容。通过与DeepMIM 结合 ,模型在多个下游任务中精度都得到了提升。
简介¶
深度学习刚兴起时,一些方法在神经网络的中间特征使用额外监督,这被广泛应用于各自视觉任务。例如,GoogLeNet 在它的中间特征上使用额外的损失,以保证梯度下降的效率,并改善对网络浅层的正则化。但是,随着批量归一化(BN)和残差连接的出现,图像分类中的深度监督学习受到的关注较少,这似乎大大缓解了与梯度消失相关的问题。本文作者重新审视Masked Image Modeling (MIM) 中的监督学习,这是用于ViT的自监督预训练策略。由于将 MIM 预训练模型传输到下游任务时,保留编码器而丢弃解码器。结果,解码器在预训练阶段隐式加深了网络,使得编码器的较浅层从监督信号接收到的信息反馈较弱。最近的 MIM 工作研究了什么样的重建目标是恰当的这个问题。本文工作致力于研究 MIM 预训练的正交部分:即应该在哪里应用重建损失?因此,本文的 DeepMIM 与广泛的编码解码器 MIM 模型兼容,同时,这是一种基于ViT的预训练框架,主要贡献总结如下:
(1) 重新思考 MIM 预训练的深度监督。与以前的 MIM 工作探索适当的重建目标应该采用什么形式不同,作者关注一个正交方向:在哪里应用重建损失。并深入研究了在 MIM 预训练中引入深度监督的好处,发现它导致重建损失更低、头部更多样化,以及更浅层的表示能力更强大。
(2) 提出了一个称为混合目标生成器的可选模块,它进一步提高了性能但涉及额外的计算开销。
(3) DeepMIM 是对大多数现有 MIM 方法的补充。大量实验表明,配备 DeepMIM 的 MIM 模型明显优于非 DeepMIM 模型。例如,使用 ViT-B,带有 DeepMIM 的 MAE 在 ImageNet 上达到了 84.2 的 top-1 精度。包括将该方法与其他MIM模型结合,在各种下游任务上均实现了最先进的性能。
总体而言,与之前的工作不同,本文在自监督学习和MIM的背景下重新审视深度监督方法,并展示其在这种情况下的价值。
方法 Method¶
MIM任务介绍¶
Masked Image Modeling (MIM) 是将图像中的一些patches 进行屏蔽,对将剩余的一些visible patches进行特征提取,以预测被屏蔽掉的patches,从而实现图像修复/重建。
DeepMIM 提出了两种技术:1)将额外的解码器附加到编码器的中间块,以实现对 MIM 预训练的深度监督; 2)利用渐进式混合目标作为中间特征的重建目标。
模型结构¶
DeepMIM 采用编码器-多解码器架构来执行 ViT 预训练的掩码和预测任务。为了具体解释,作者使用MAE进行方法的说明。但是DeepMIM 本身是可以用于各种MIM框架的。其结构如下图所示,DeepMIM 在预训练期间对中间特征进行深度监督。每个轻量级解码器由 4 个 Transformer 块组成:
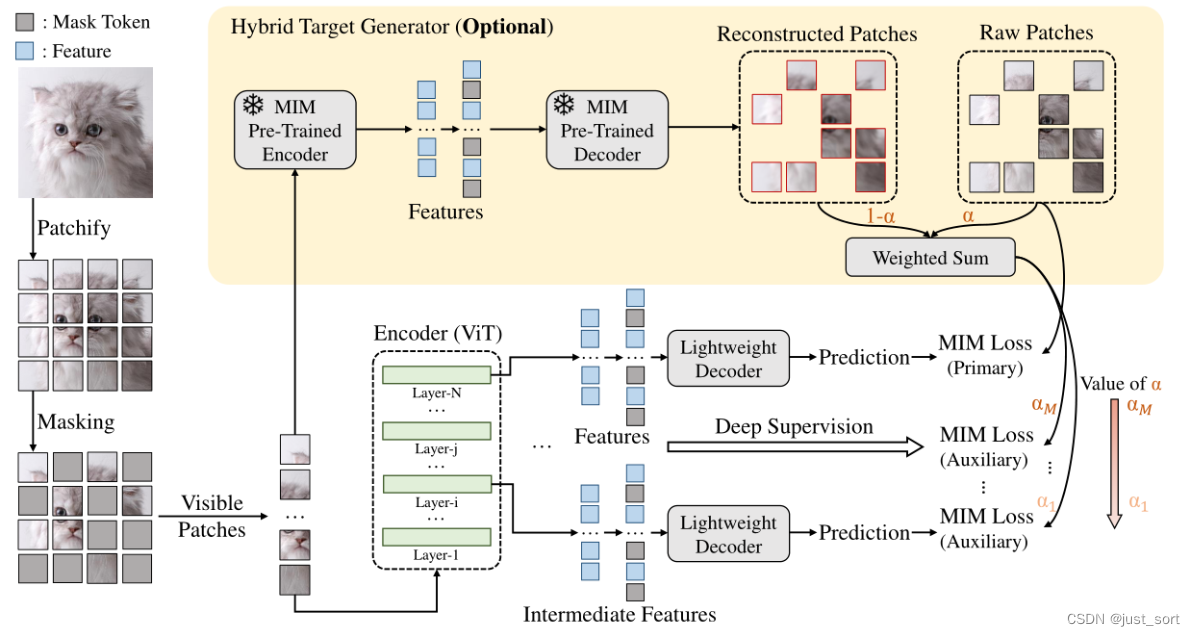
如同ViT一样,DeepMIM 将输入图像分为规则的互相不重叠patches。然后和MAE方法类似,对这些patch随机进行屏蔽,得到masked image,再将可见的patches送入编码器产生多级特征。除了最后一个 Transformer 块之外,解码器也附加到中间块。对于 ViT-B,在编码器 的第 6、8 和 10 个 Transformer 块上附加了三个额外的解码器,以促进深度监督。每个解码器都是一个独立的 4 层 Transformer,具有编码的可见patches(来自最后一个块或中间块)和屏蔽标记作为输入。得益于轻量级解码器,DeepMIM 的整体训练成本略高于 MAE,即 DeepMIM 和 MAE 在 32×NVIDIA V100 GPU 上的 1600 个 epoch 计划下分别需要 115 和 108 个训练小时。
由于ViT的浅层特征辨别能力较差,这些特征可能无法对过于复杂的目标进行重建。作者使用MAE产生的模糊重建结果作为目标,以简化中间特征的训练。混合目标 t 使用α对原始图像和重建图像进行加权混合:
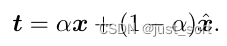
由于使用混合目标,会导致额外的计算开销,因此,作者仅在有现成的混合目标生成器(预训练 MIM 模型)时才使用它;相反,α设置为1。
损失函数¶
损失函数由M个额外的编码器和主编码器产生的共 (M+1) 个L2重建损失组成:
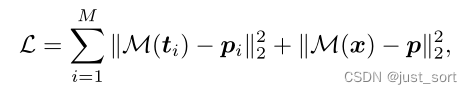
实验¶
作者使用ViT-B/16 作为backbone,输入图像分辨率为224x224大小,并且进行了多个下游任务的方法对比。其中,分类任务采用ImageNet-1K数据集,检测任务使用COCO 数据集作为基准,分割任务采用ADE20K 数据集进行评估。此外,还在Kinetics-400上进行视频分类。多数据集上的对比结果,表明DeepMIM对下游任务较强的可迁移性。
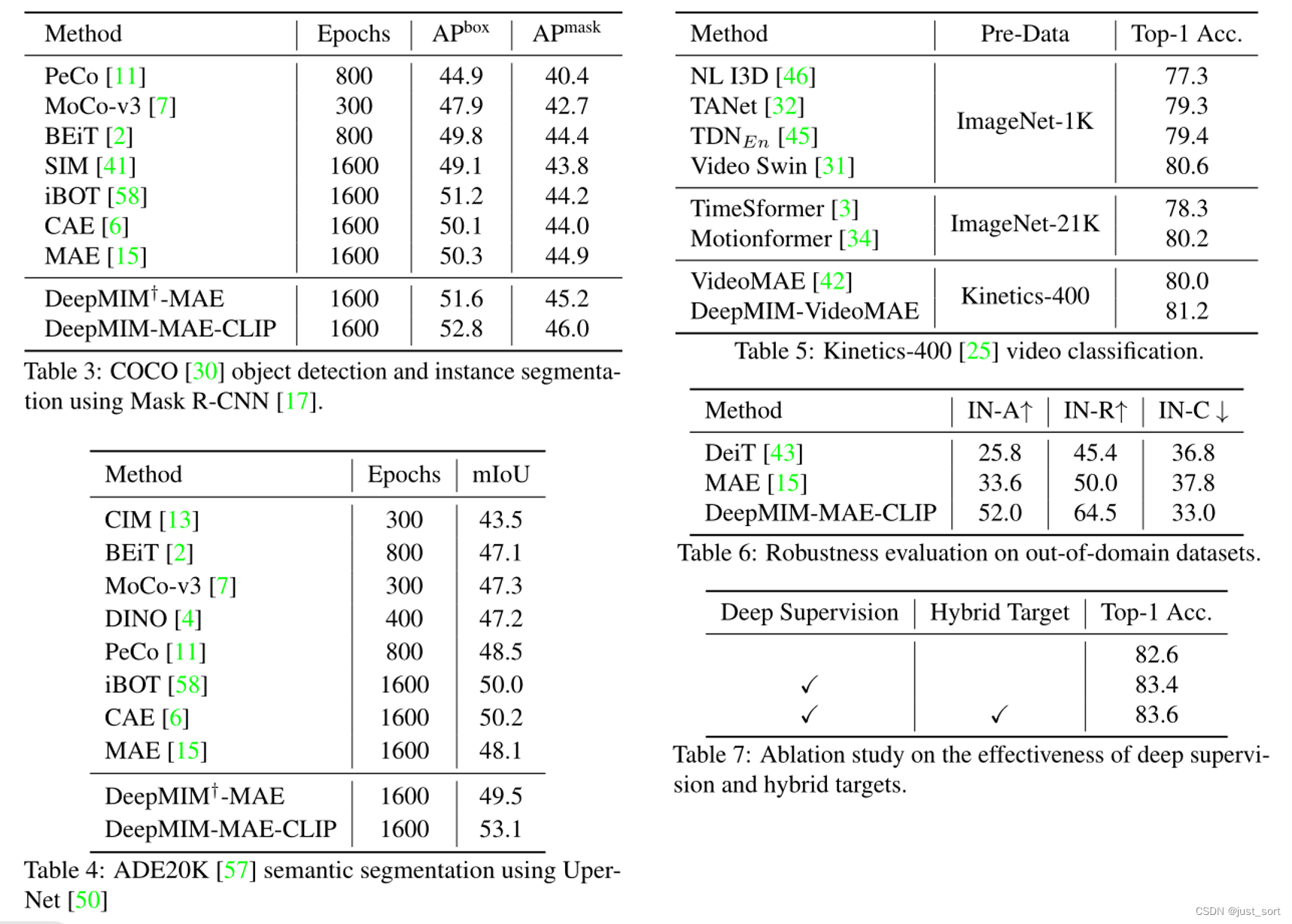
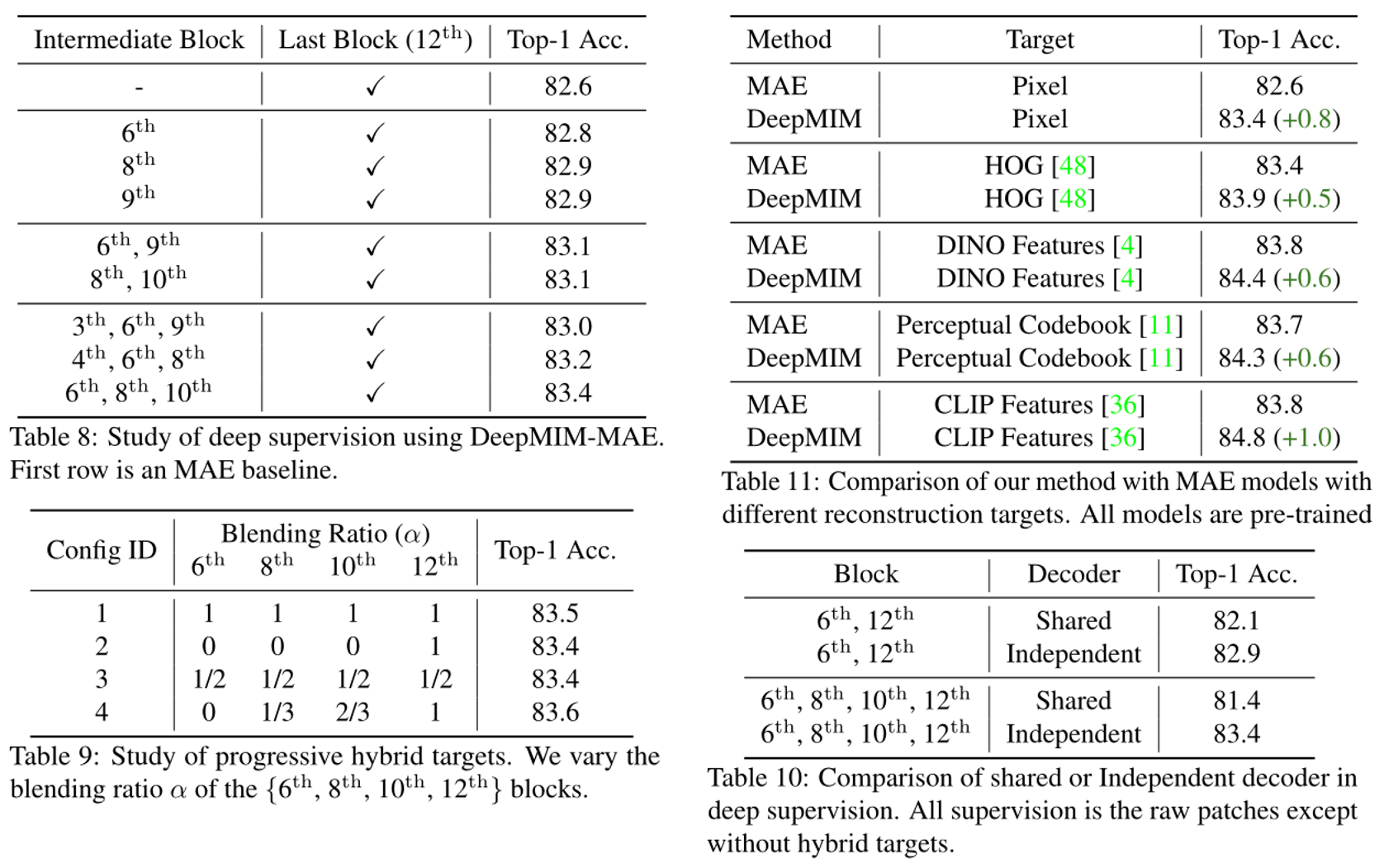
为了对所提的两个技术进行验证,文章进行了大量实验。本文将附加的解码器加在编码器中间块上,为了探索两个问题:(1) 在哪里应用深度监督;(2) 应该加多少块,这部分实验结果图Table 8所示。并且,通过混合原始信号和重建信号来为不同的中间块生成混合目标(Table 9),混合比为 α 控制它们之间的比率。而且,通过对中间特征层附加的解码器进行了消融实验(Table 10),共享解码器的精度低于独立解码器,这是由于不同块的特征分布各不相同。此外,作者将 DeepMIM 应用于不同的 MAE 变体,精度都优于原先的MIM模型。
结论 Conclusion¶
本文将重点从设计重建目标转移到在何处应用重建损失的问题,发现来自较浅 Transformer 块的中间特征也具有重建的预测能力,并且在训练期间改进这些特征可以提高整个模型的学习表征质量,从而提出了 DeepMIM,它通过额外的解码器和混合目标对中间特征进行深度监督,为鉴别力较低的中间特征提供适当的监督。同时,实验表明,DeepMIM 与一系列MIM框架兼容,并在强大的基线基础上产生一致的改进。
本文总阅读量次