前言¶
昨天介绍了YOLO系列的第一个算法YOLOv1,并详细分析了YOLOv1的网络结构以及损失函数等。今天我们将来分析一下YOLO目标检测算法系列的YOLOv2和YOLO9000。
YOLOv2¶
原理¶
YOLOv1作为One-Stage目标检测算法的开山之作,速度快是它最大的优势。但我们知道,YOLOv1的定位不够准,并且召回率低。为了提升定位准确度,提高召回率,YOLOv2在YOLOv1的基础上进行了改进。具体的改进方法如图Fig1所示:
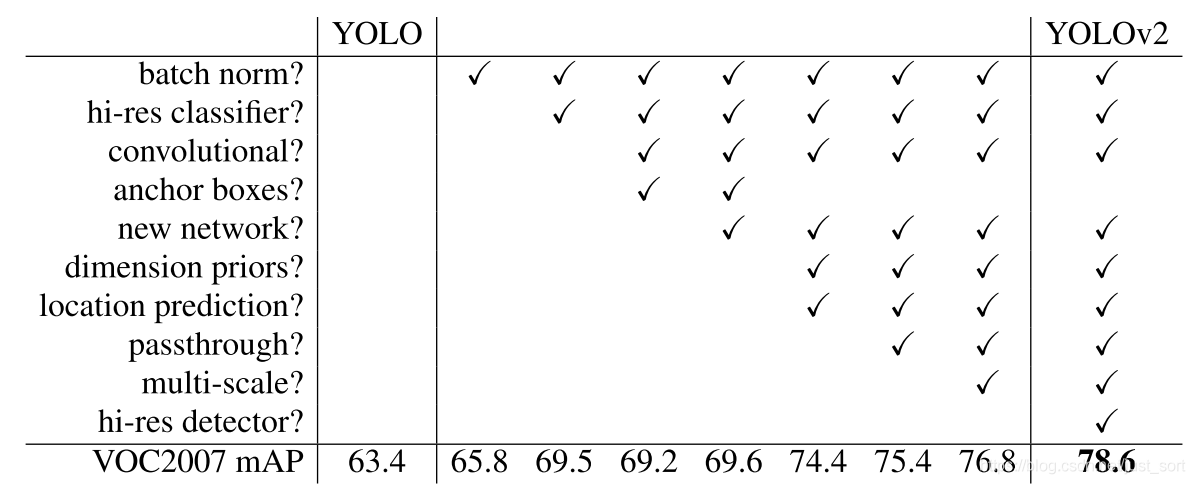
可以看到YOLOv2通过增加一些Trick使得v1的map值从63.4提高到了78.6,说明了YOLOv2改进方法的有效性。接下来我们就分析一下这些改进方法。
批量归一化¶
这个应该不用多说了,YOLOv2在每个卷积层后面增加了VB层,去掉全连接的dropout。使用BN策略将map值提高了2%。
高分辨率¶
当前大多数目标检测网络都喜欢使用主流分类网络如VGG,ResNet来做Backbone,而这些网络大多是在ImageNet上训练的,而分辨率的大小必然会影响到模型在测试集上的表现。所以,YOLOv2将输入的分辨率提升到448\times 448,同时,为了使网络适应高分辨率,YOLOv2先在ImageNet上以448\times 448的分辨率对网络进行10个epoch的微调,让网络适应高分辨率的输入。通过使用高分辨率的输入,YOLOv2将map值提高了约4%。
基于卷积的Anchor机制¶
YOLOv1利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位不准。YOLOv2去掉了YOLOv1中的全连接层,使用Anchor Boxes预测边界框,同时为了得到更高分辨率的特征图,YOLOv2还去掉了一个池化层。由于图片中的物体都倾向于出现在图片的中心位置,若特征图恰好有一个中心位置,利用这个中心位置预测中心点落入该位置的物体,对这些物体的检测会更容易。所以总希望得到的特征图的宽高都为奇数。YOLOv2通过缩减网络,使用416x416的输入,模型下采样的总步长为32,最后得到13x13的特征图,然后对13x13的特征图的每个cell预测5个anchor boxes,对每个anchor box预测边界框的位置信息、置信度和一套分类概率值。使用anchor
boxes之后,YOLOv2可以预测13x13x5=845个边界框,模型的召回率由原来的81%提升到88%,mAP由原来的69.5%降低到69.2%.召回率提升了7%,准确率下降了0.3%。这里我们和SSD以及Faster-RCNN做个对比,Faster RCNN输入大小为1000*600时的boxes数量大概是6000,在SSD300中boxes数量是8732。显然增加box数量是为了提高object的定位准确率。
维度聚类¶
在Faster-RCNN中,Anchor都是手动设定的,YOLOv2使用k-means聚类算法对训练集中的边界框做了聚类分析,尝试找到合适尺寸的Anchor。另外作者发现如果采用标准的k-means聚类,在box的尺寸比较大的时候其误差也更大,而我们希望的是误差和box的尺寸没有太大关系。所以通过IOU定义了如下的距离函数,使得误差和box的大小无关:
d(box,centroid)=1-IOU(box,centroid)
Fig2展示了聚类的簇的个数和IOU之间的关系,两条曲线分别代表了VOC和COCO数据集的测试结果。最后结合不同的K值对召回率的影响,论文选择了K=5,Figure2中右边的示意图是选出来的5个box的大小,这里紫色和黑色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。而且发现聚类的结果和手动设置的anchor box大小差别显著。聚类的结果中多是高瘦的box,而矮胖的box数量较少,这也比较符合数据集中目标的视觉效果。
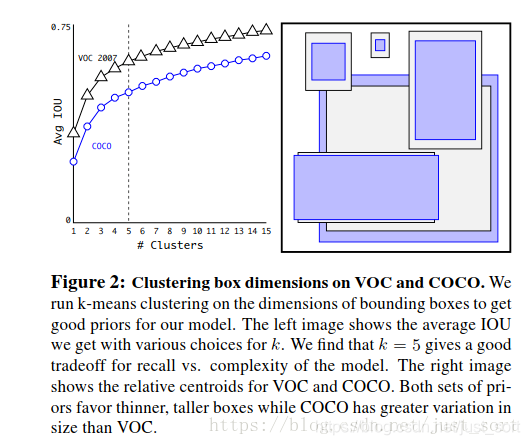
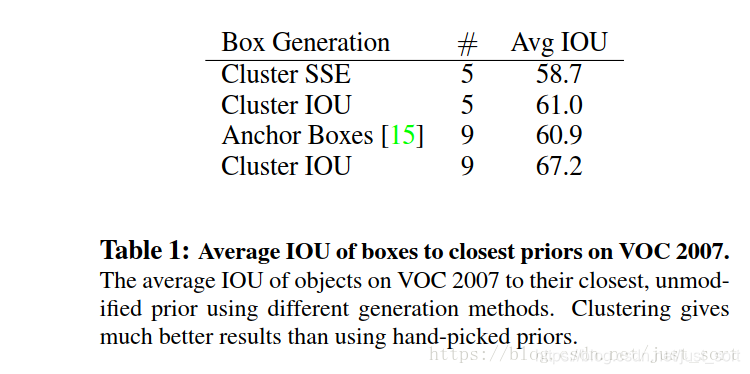
在结果测试时,YOLOv2采用的5种Anchor可以达到的Avg IOU是61,而Faster-RCNN采用9种Anchor达到的平均IOU是60.9,也即是说本文仅仅选取5种Anchor就可以达到Faster-RCNN中9种Anchor的效果。如Table1所示:
新Backbone:Darknet-19¶
YOLOv2采用Darknet-19,其网络结构如下图所示,包括19个卷积层和5个max pooling层,主要采用3\times 3卷积和1\times 1卷积,这里1\times 1卷积可以压缩特征图通道数以降低模型计算量和参数,每个卷积层后使用BN层以加快模型收敛同时防止过拟合。最终采用global avg pool 做预测。采用YOLOv2,模型的mAP值没有显著提升,但计算量减少了。

直接位置预测¶
YOLOv2在引入Anchor的时候碰到第2个问题:模型不稳定,尤其是训练刚开始阶段。论文任务这种不稳定主要来自box的(x,y)预测值。我们知道在Faster-RCNN中,是通过预测下图中的tx和ty来得到(x,y)值,也就是预测的是offset。另外关于文中的这个公式,这个地方应该把后面的减号改成加号,这样才能符合公式下面的example。这里x_a和y_a是anchor的坐标,w_a和h_a是anchor的size,x和y是坐标的预测值,t_x和t_y是偏移量。

例子翻译过来是:当预测t_x=1时,就会把box向右边移动一定距离(具体为anchor box的宽度),预测t_x=-1时,就会把box向左边移动相同的距离。 这个公式没有任何限制,使得无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点结束,模型随机初始化后,需要花很长一段时间才能稳定预测敏感的物体位置。.
注意,高能来了!!! 分析了原因之后,YOLOv2没有采用直接预测offset的方法,还是沿用了YOLO算法中直接预测相对于grid cell的坐标位置的方式。前面提到网络在最后一个卷积层输出13*13大小的特征图,然后每个cell预测5个bounding box,然后每个bounding box预测5个值:t_x,t_y,t_w,t_h和t_o(这里的t_o类似YOLOv1中的confidence)。t_x和t_y经过sigmoid函数处理后范围在0到1之间,这样的归一化处理使得模型训练更加稳定。c_x和c_y表示一个cell和图像左上角的横纵距离。p_w和p_h表示bounding box的宽高,这样bx和by就是cx和cy这个cell附近的anchor来预测tx和ty得到的结果。如Fig3所示:

其中,c_x和c_y表示grid cell与图像左上角的横纵坐标距离,黑色虚线框是bounding box,蓝色矩形框就是最终预测的结果。注意,上图右边里面的\delta(t_x)可以理解为st_x,\delta(t_y)可以理解为st_y。每一个输出的bounding box是针对于一个特定的anchor,anchor其实是bounding box的width及height的一个参考。p_w和p_h是某个anchor box的宽和高,一个格子的Cx和Cy单位都是1,\delta(t_x),\delta(t_y)是相对于某个格子左上角的偏移量。
细粒度特征¶
YOLOv2提取Darknet-19最后一个max pool层的输入,得到26x26x512的特征图。经过1x1x64的卷积以降低特征图的维度,得到26x26x64的特征图,然后经过pass through层的处理变成13x13x256的特征图(抽取原特征图每个2x2的局部区域组成新的channel,即原特征图大小降低4倍,channel增加4倍),再与13x13x1024大小的特征图连接,变成13x13x1280的特征图,最后在这些特征图上做预测。使用Fine-Grained Features,YOLOv2的性能提升了1%。这个过程可以在下面的YOLOv2的结构图中看得很清楚:

多尺度训练¶
OLOv2中使用的Darknet-19网络结构中只有卷积层和池化层,所以其对输入图片的大小没有限制。YOLOv2采用多尺度输入的方式训练,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸,由于Darknet-19下采样总步长为32,输入图片的尺寸一般选择32的倍数{320,352,…,608}。采用Multi-Scale Training, 可以适应不同大小的图片输入,当采用低分辨率的图片输入时,mAP值略有下降,但速度更快,当采用高分辨率的图片输入时,能得到较高mAP值,但速度有所下降。
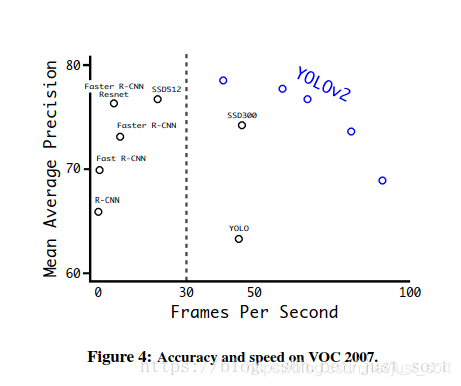
这种机制使得网络可以更好地预测不同尺寸的图片,意味着同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。 在小尺寸图片检测中,YOLOv2成绩很好,输入为228 * 228的时候,帧率达到90FPS,mAP几乎和Faster R-CNN的水准相同。使得其在低性能GPU、高帧率视频、多路视频场景中更加适用。在大尺寸图片检测中,YOLOv2达到了SOAT结果,VOC2007 上mAP为78.6%,仍然高于平均水准,下图是YOLOv2和其他网络的精度对比:
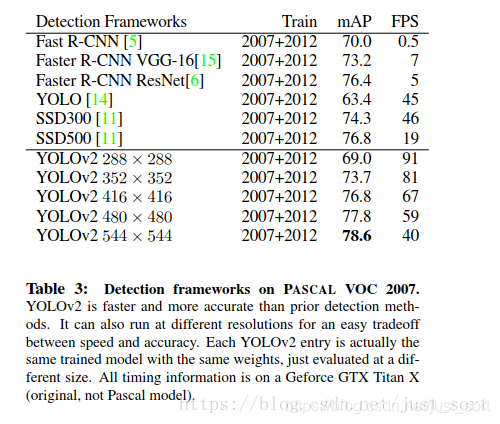
速度对比:
训练¶
YOLOv2的训练主要包括三个阶段。 第一阶段:作者使用Darknet-19在标准1000类的ImageNet上训练了160次,用的随机梯度下降法,starting learning rate 为0.1,polynomial rate decay 为4,weight decay为0.0005 ,momentum 为0.9。训练的时候仍然使用了很多常见的数据扩充方法(data augmentation),包括random crops, rotations, and hue, saturation, and exposure shifts。 (这些训练参数是基于darknet框架,和caffe不尽相同)初始的224 * 224训练后,作者把分辨率上调到了448 * 448,然后又训练了10次,学习率调整到了0.001。高分辨率下训练的分类网络在top-1准确率76.5%,top-5准确率93.3%。
第二个阶段:分类网络训练完后,就该训练检测网络了,作者去掉了原网络最后一个卷积层,转而增加了三个3 * 3 * 1024的卷积层(可参考darknet中cfg文件),并且在每一个上述卷积层后面跟一个1 * 1的卷积层,输出维度是检测所需的数量。对于VOC数据集,预测5种boxes大小,每个box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。同时也添加了转移层(passthrough layer ),从最后那个3 * 3 * 512的卷积层连到倒数第二层,使模型有了细粒度特征。作者的检测模型以0.001的初始学习率训练了160次,在60次和90次的时候,学习率减为原来的十分之一。其他的方面,weight decay为0.0005,momentum为0.9,依然使用了类似于Faster-RCNN和SSD的数据扩充(data augmentation)策略。
总结¶
YOLOv2借鉴了很多其它目标检测方法的一些技巧,如Faster R-CNN的anchor boxes, SSD中的多尺度检测。除此之外,YOLOv2在网络设计上做了很多tricks,使它能在保证速度的同时提高检测准确率,Multi-Scale Training更使得同一个模型适应不同大小的输入,从而可以在速度和精度上进行自由权衡。
本文总阅读量次