推荐阅读: - 一文弄懂 Diffusion Model - 35张图,直观理解Stable Diffusion - 如何简单高效地定制自己的文本作画模型? - Diffusion Model的演进 NeurIPS 2022最佳论文:Imagen - 不需要训练来纠正文本生成图像模型的错误匹配
A Generalist Framework for Panoptic Segmentation of Images and Videos¶
标题:A Generalist Framework for Panoptic Segmentation of Images and Videos
作者:Ting Chen, Lala Li, Saurabh Saxena, Geoffrey Hinton, David J. Fleet
原文链接:https://arxiv.org/pdf/2210.06366.pdf
2. 引言¶
首先回顾一下全景分割的设定。全景分割(PS,Panoptic Segmentation)的task format不同于经典的语义分割,它要求每个像素点都必须被分配给一个语义标签(stuff、things中的各个语义)和一个实例id。具有相同标签和id的像素点属于同一目标;对于stuff标签,不需要实例id。与实例分割相比,目标的分割必须是非重叠的(non-overlapping),因此对那些每个目标单独标注一个区域是不同的。虽然语义标签的类类别是先验固定的,但分配给图像中对象的实例 ID 可以在不影响识别的实例的情况下进行排列。因此,经过训练以预测实例 ID 的神经网络应该能够学习一对多映射,从单个图像到多个实例 ID 分配。 一对多映射的学习具有挑战性,传统方法通常利用涉及对象检测、分割、合并多个预测的多个阶段的管道这有效地将一对多映射转换为基于识别匹配的一对一映射。这篇论文的作者将全景分割任务制定为条件离散数据生成问题,如下图所示。 本文是大名鼎鼎的Hinton参与的工作,非常有意思,又是基于diffusion model模式的生成模型来完成全景分割,将mask其视为一组离散标记,以输入图像为条件,预测得到完整的分割信息。
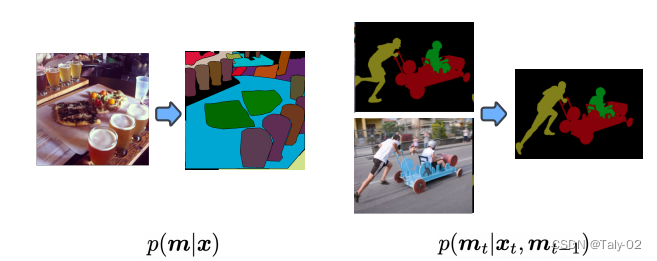
全景分割的生成式建模非常具有挑战性,因为全景掩码是离散的,或者说是有类别的,并且模型可能非常大。例如,要生成 512×1024 的全景掩码,模型必须生成超过 1M 的离散标记(语义标签和实例标签)。这对于自回归模型来说计算开销是比较大的,因为 token 本质上是顺序的,很难随着输入数据的规模变化而变化。扩散模型更擅长处理高维数据,但它们最常应用于连续域而不是离散域。通过用模拟位表示离散数据,本文作者表明可以直接在大型全景分割上完成diffusion的训练,而不需要在latent space进行学习。这样就使得模型 这对于自回归模型来说是昂贵的,因为它们本质上是顺序的,随着数据输入的大小缩放不佳。 diffusion model很擅长处理高维数据,但它们最常应用于连续而非离散域。 通过用模拟位表示离散数据,论文表明可以直接在大型全景掩模上训练扩散模型,而无需学习中间潜在空间。接下来,我们来介绍本文提出的基于扩散的全景分割模型,描述其对图像和视频数据集的广泛实验。 在这样做的过程中,论文证明了所提出的方法在类似设置中与最先进的方法相比具有竞争力,证明了一种新的、通用的全景分割方法。
3. 方法¶
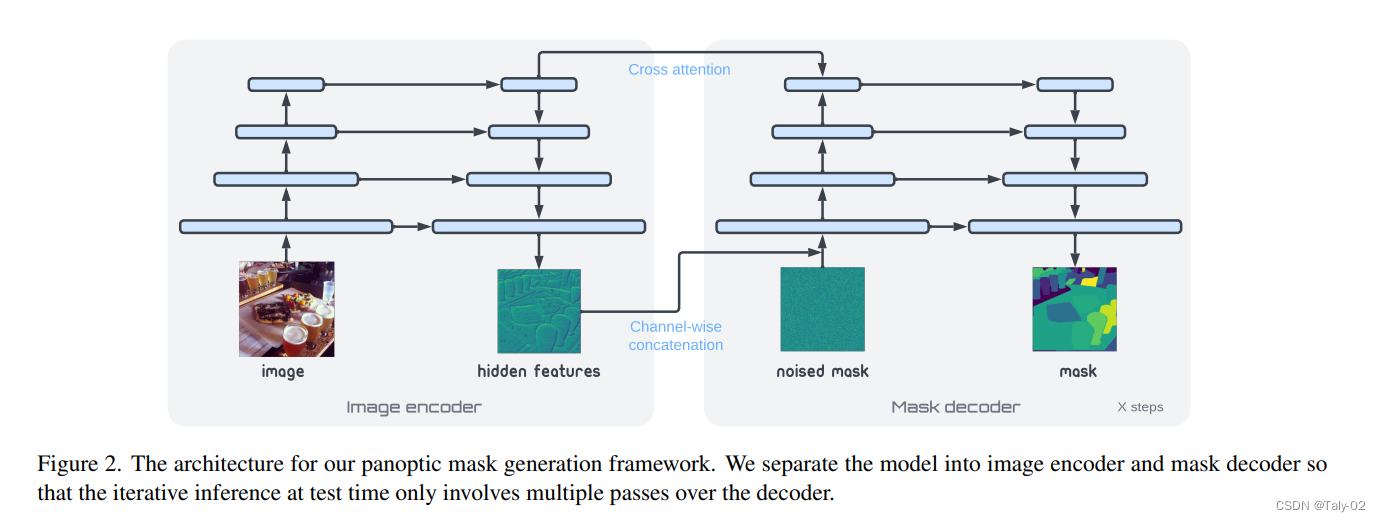
扩散模型采样是迭代的,因此在推理过程中必须多次运行网络的前向传递。 因此,如上图,论文的结构主要分为两个部分:1)图像编码器; 2)mask的解码器。前者将原始像素数据映射到高级表示向量,然后掩模解码器迭代地读出全景掩模。
首先来看encoder的组成。编码器是一个网络,它将原始图像 {x} \in \mathbb{R}^{H\times W\times 3} 映射到 \mathbb{R}^{H'\times W' \times d} 其中 H' 和 W' 是全景分割的高度和宽度。通过这样的映射,可以使得全景分割得到的hidden features的分辨率可以与原始图像大小相同或更小。受到 U-Net和特征金字塔网络(pyramids feature network)的启发,论文提出使用带有双边连接的卷积和上采样操作来合并来自不同分辨率的特征,这样就可以确保输出特征图具有足够的分辨率,并包含不同尺度的特征。
而对于decoder,也是比较直接的。首先明确解码器在模型中起到的作用主要是基于图像特征,迭代地细化全景掩码。具体来说,研究者使用的掩码解码器是 Trans-UNet。该网络将来自编码器的图像特征图和噪声掩码(随机初始化或迭代地来自编码过程)的连接作为输入,并输出对掩码的精确预测。解码器与用于图像生成和图像到图像转换的标准 U-Net 架构之间的一个区别是,在上采样之前,本文使用的 U-Net 顶部使用了带有交叉注意力层的 transformer 解码器层来合并编码的图像特征。

算法的block如上所示,可以看到还是非常清晰的,主要的步骤就是编码解码,然后diffusion。
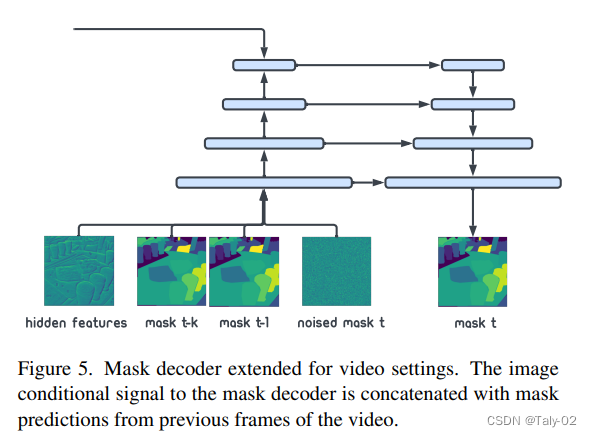
那么如何完成视频里的应用呢?对于图像条件下的全景遮罩建模为:p(m|x)。基于给定视频的三维掩码(有一个额外的时间维度),本文的模型就可以直接适用于视频全景分割。我们知道现有的视频模型往往是基于stream的,再用p(m|x)进行建模就可能受限制,所以不妨把这个结构改成多个条件概率,用 p(m_t|x_t,m_{t-1},m_{t-k})建模这一结构,从而基于当前的图像和上一时刻的掩码生成新的全景掩码。如图 5 所示,这一变化可以通过将过去的全景掩码 m_{t-1},m_{t-k} 与现有的噪声掩码连接起来来实现。除了这个微小的变化之外,其他方面都与视频基础模型p(m|x)相同。其实总结来看,与图像仅仅只是MCMC这个过程中的条件概率公式有所不同,模型还是一样的简单,所以本文提出的模型仅仅需要对图像的模型进行fine-tuning,就可以拓展倒视频场景的应用中。
4. 实验¶
来看实验结果:
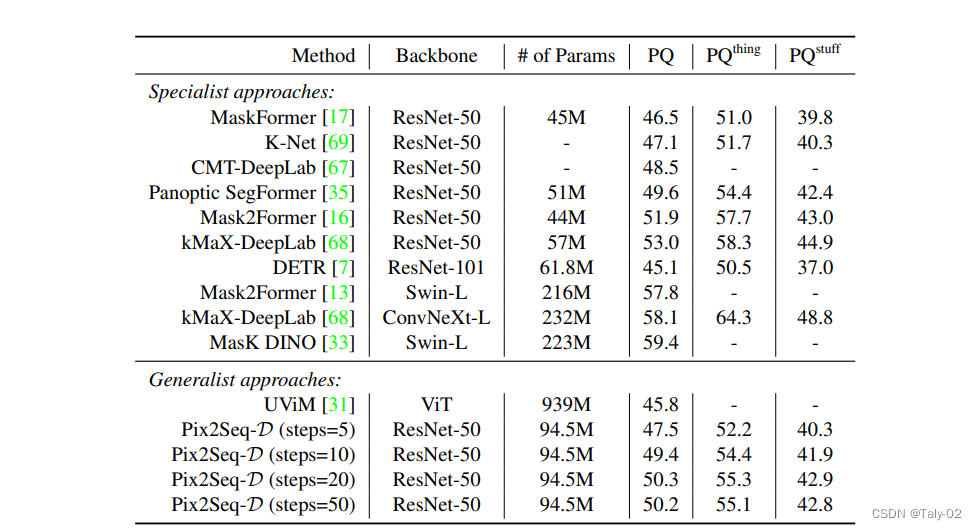
在 MS-COCO 数据集上,Pix2Seq-D 在基于 ResNet-50 的主干上的泛化质量(PQ)与最先进的方法相比有一定的竞争力。与最近的其他通用模型如 UViM 相比,本文的模型表现明显更好,同时效率更高。
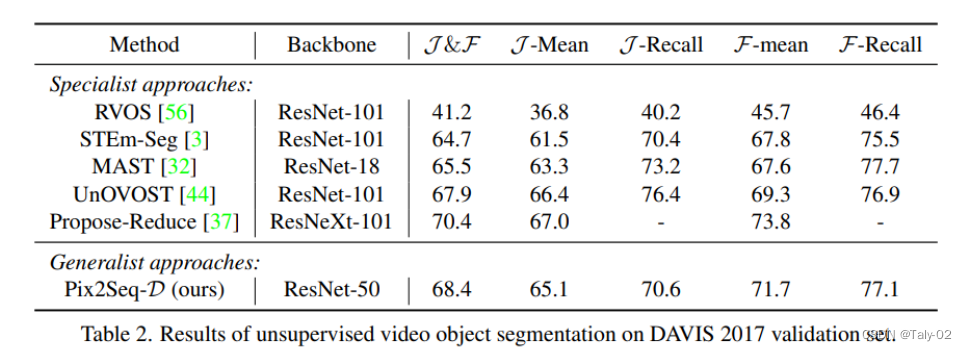
而在无监督数据集DAVIS上,也有更优的表现。
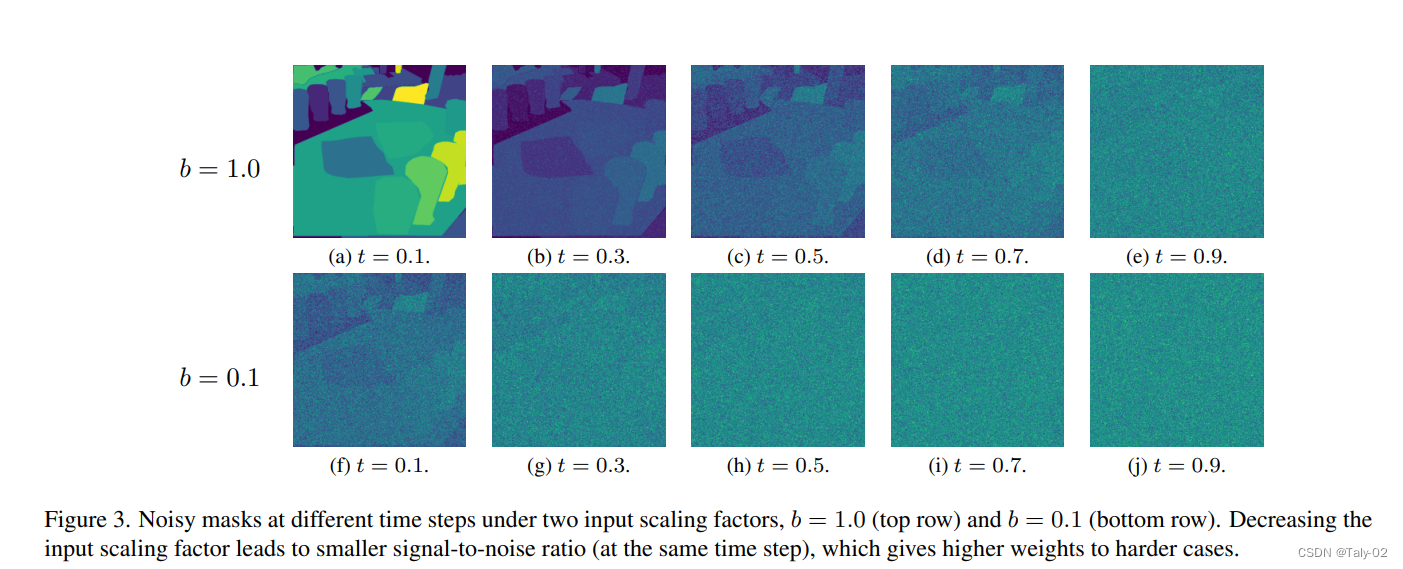
论文还提供了一个比较有趣的可视化,可以发现减少输入比例因子导致更小的信噪比(在相同的时间步长),从而为更困难的情况赋予更高的权重。
5. 结论¶
本文基于离散全景蒙版的条件生成模型,提出了一种用于图像和视频全景分割的新型通用框架。 通过利用强大的Bit Diffusion 模型,我们能够对大量离散token建模,这对于现有的通用模型来说是困难的。
本文总阅读量次